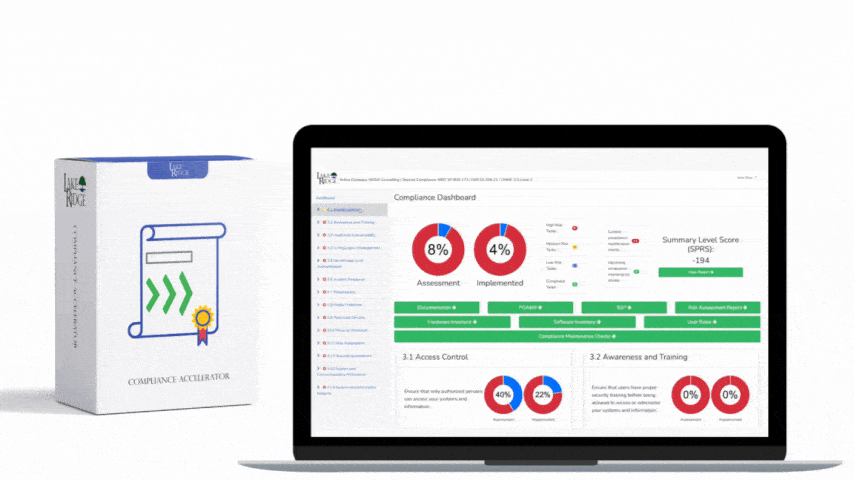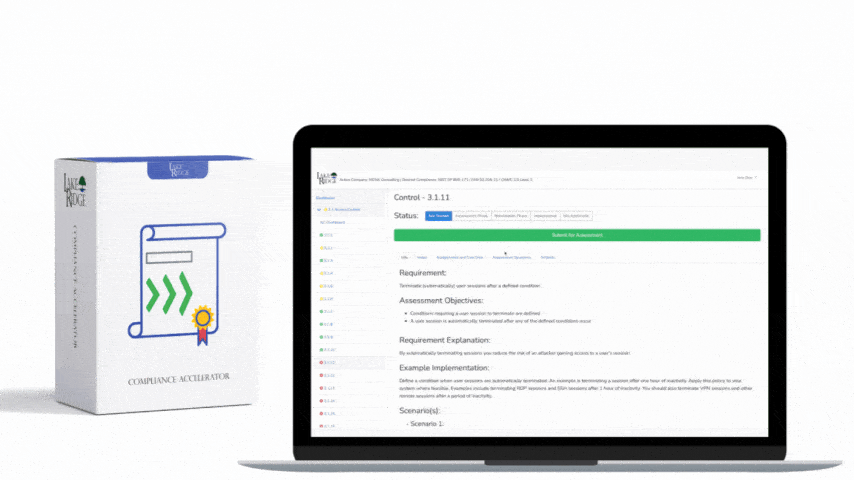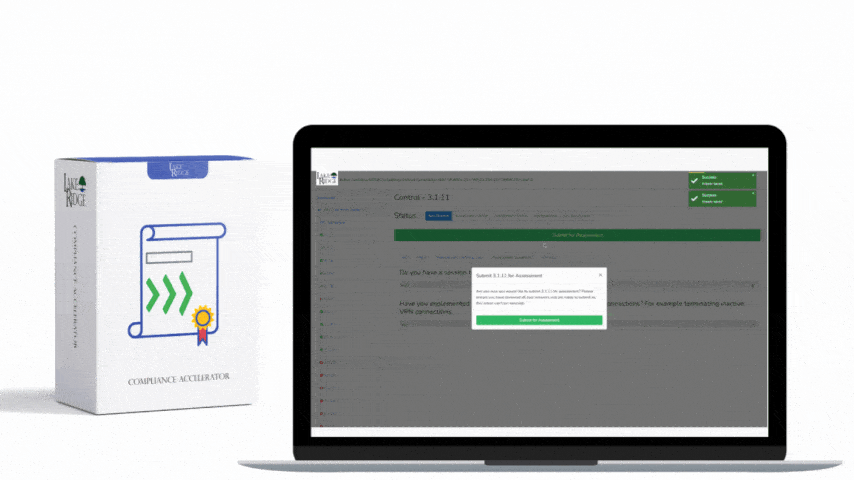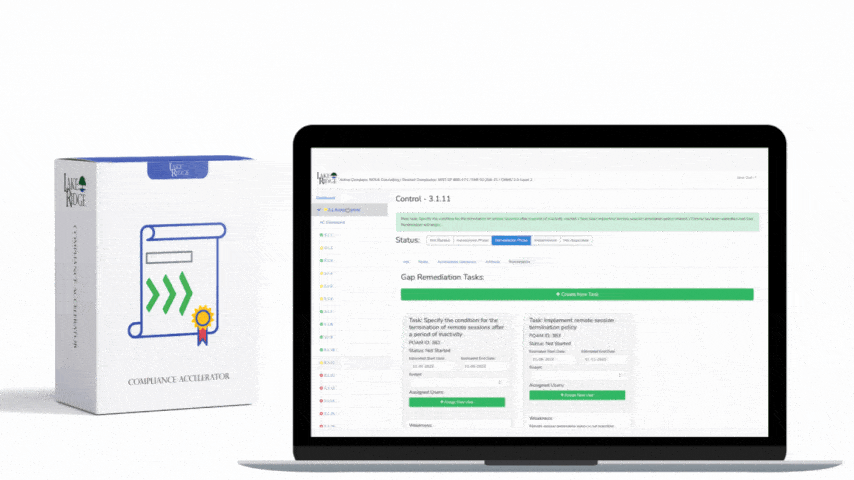
This post shows step-by-step, actionable ways to detect and automatically alert when AWS audit logging fails (CloudTrail stops, delivery errors, or log absence) so small organizations can meet NIST SP 800-171 REV.2 / CMMC 2.0 Level 2 control AU.L2-3.3.4 and maintain reliable forensic telemetry for Controlled Unclassified Information (CUI).
Overview of the requirement and how it maps to AWS
NIST / CMMC require organizations to ensure audit logging is reliable and that failures are detected and reported. In AWS this translates to monitoring CloudTrail trails, the delivery pipeline to S3/CloudWatch Logs, and any operational events that could stop logging or cause loss of records. Practical automation uses a combination of CloudTrail, CloudWatch (metrics and alarms), EventBridge (CloudTrail API event detection), SNS for notifications, and optional Lambda health-checks for richer status evaluation.
Risk of not implementing automated alerts
If logging failures go unnoticed you lose visibility into privileged operations and potential compromises. For a small business this could mean missing insider misuse, failing forensic timelines after a breach, losing CUI traceability, breaching contractual requirements, and risking audit failures or termination. Even transient delivery errors (S3 permissions or bucket lifecycle misconfigurations) can create gaps attackers will exploit.
Design patterns and practical implementation options
There are three reliable patterns you can use individually or together: (A) EventBridge rule to catch CloudTrail API events that stop or delete logging; (B) periodic Lambda health-check that calls GetTrailStatus and evaluates delivery error fields; and (C) CloudWatch Logs metric filters (or scheduled Logs Insights queries) to detect absence of events. Use multi-region trails and cross-account aggregation where possible so a single monitoring pipeline covers all regions and accounts.
Option A — EventBridge (immediate, low-effort detections)
Create an EventBridge rule that looks for CloudTrail API calls which indicate logging has been stopped or a trail changed. Example event pattern (JSON) to detect StopLogging, DeleteTrail or UpdateTrail calls:
{
"source": ["aws.cloudtrail"],
"detail-type": ["AWS API Call via CloudTrail"],
"detail": {
"eventName": ["StopLogging", "DeleteTrail", "UpdateTrail"]
}
}
Set the target to an SNS topic (email/SMS) or a Lambda that escalates to PagerDuty. This catches administrator mistakes and malicious API calls in real time. Require IAM conditions that prevent unauthorized StopLogging where feasible.
Option B — Lambda health-check (most comprehensive)
Use a scheduled EventBridge rule (every 1–5 minutes) to invoke a small Lambda that calls cloudtrail.get_trail_status(Name='my-trail'). Key fields to check: IsLogging (boolean), LatestDeliveryError (string), TimeLoggingStopped, and TimeLastDeliveryAttempt. If IsLogging is false or LatestDeliveryError is non-empty (or last delivery time is too old), Lambda publishes to SNS for immediate response. Minimal Python example (boto3):
import boto3
ct = boto3.client('cloudtrail')
sns = boto3.client('sns')
TRAIL_NAME = 'my-trail'
SNS_ARN = 'arn:aws:sns:us-east-1:123456789012:ct-alerts'
def lambda_handler(event, context):
status = ct.get_trail_status(Name=TRAIL_NAME)
if not status.get('IsLogging') or status.get('LatestDeliveryError'):
message = f"CloudTrail problem: IsLogging={status.get('IsLogging')} LatestDeliveryError={status.get('LatestDeliveryError')}"
sns.publish(TopicArn=SNS_ARN, Message=message, Subject='ALERT: CloudTrail Logging Failure')
Grant the Lambda role cloudtrail:GetTrailStatus and sns:Publish. This approach validates the internal trail state and delivery pipeline (S3 permissions, KMS errors, etc.) and is robust for small teams that want one source of truth.
Option C — CloudWatch Logs / Metric filter (detect missing events)
If your trail is streaming to CloudWatch Logs, create a metric filter that counts CloudTrail events (e.g., filter for "eventTime" which is present in every CloudTrail JSON event). Then create a CloudWatch alarm that triggers when the count falls below an expected threshold for a period (e.g., fewer than 1 event in 5 minutes in an active environment). Steps: 1) Configure CloudTrail to send to CloudWatch Logs. 2) In CloudWatch Logs > Metric Filters create a filter with pattern "eventTime" and emit metric 'CloudTrailEvents'. 3) Create Alarm on metric for threshold & evaluation periods. This detects gaps in event volume that may indicate stopped delivery.
Real-world small-business scenarios
Example 1 — Developer accident: A developer updates the shared CloudTrail using the console and unintentionally disables logging in us-east-1. EventBridge rule detects the StopLogging API call and immediately notifies the security lead. Example 2 — S3 bucket policy change: A misconfigured bucket policy prevents CloudTrail PutObject; Lambda health-check sees LatestDeliveryError populated, sends an alert, and the DevOps engineer rolls back the policy. Example 3 — Region outage / forgotten region: A startup only had a single-region trail; metric-filter alarms showed no events from a newly launched region — prompting them to enable a multi-region trail and centralize logs into a logging account.
Compliance tips and operational best practices
Best practices to satisfy NIST/CMMC expectations: enable a multi-region, organization-level trail that delivers to a centralized, separate logging account with S3 bucket encryption, access controls, and log-file validation enabled; enable CloudTrail log file integrity validation; retain logs according to policy; integrate alerts into your incident response playbook with runbooks and owners; test alerts quarterly and run simulated StopLogging events; give monitoring roles least privilege (cloudtrail:GetTrailStatus, logs:DescribeLogGroups, sns:Publish). Document all detections, triage steps, and remediation actions to show auditors that alerts map to response procedures.
In short, combine EventBridge for real-time API detection, a Lambda-based health-check for authoritative trail status and delivery errors, and CloudWatch metric filters/alarms for volume-based gap detection. Secure SNS endpoints (use HTTPS subscription endpoints for webhooks and MFA-protected IAM for critical changes) and keep an audit trail of who acknowledged alerts.
Summary: Implementing automated alerts for audit logging failures in AWS is achievable with small investment: create EventBridge rules to catch suspicious API calls, schedule a Lambda to poll get_trail_status for authoritative failures, and add CloudWatch metric filters or Logs Insights queries to detect missing event volume. These controls reduce risk of undetected logging gaps, help you meet NIST SP 800-171 / CMMC AU.L2-3.3.4 requirements, and preserve the forensic evidence necessary to protect CUI in a small-business environment.