This guide walks you through an 8-step, practical implementation plan to satisfy NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 control SI.L2-3.14.6 (monitoring egress and ingress traffic) with specific technical actions, small-business scenarios, and compliance best practices that you can operationalize this quarter.
Requirement and key objectives
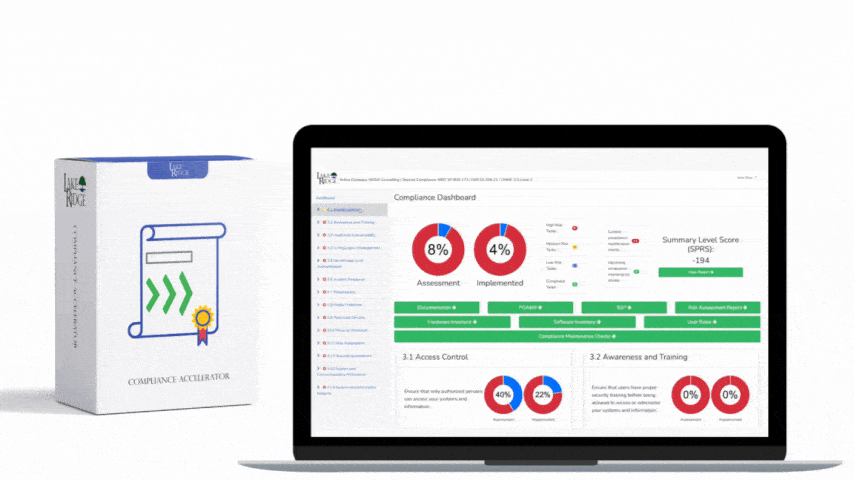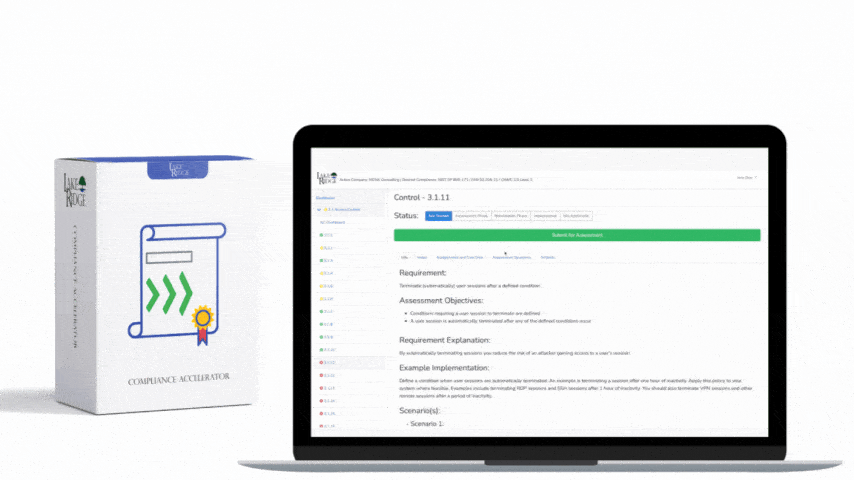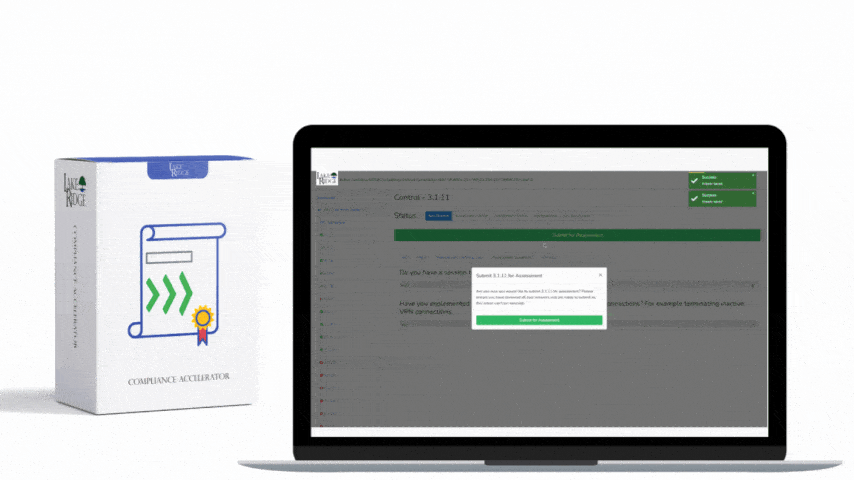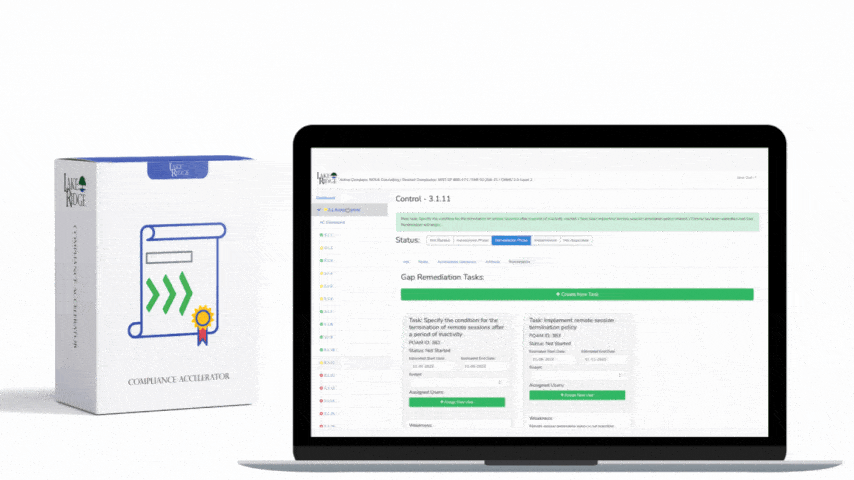
SI.L2-3.14.6 requires organizations handling Controlled Unclassified Information (CUI) to monitor and manage network egress and ingress so exfiltration and malicious inbound activity are detected and acted on; key objectives are (1) visibility across edge and internal chokepoints, (2) reliable logging and retention suitable for investigations, and (3) alerting and response workflows tied into the organization's incident response and POA&M processes.
8-Step Implementation Guide
Step 1 — Define scope and classify traffic
Step 2 — Inventory ingress and egress choke points
Start by explicitly defining what systems, subnets, and cloud resources in scope carry CUI and which network interfaces represent ingress/egress (internet gateways, VPN concentrators, cloud NATs, remote access bastions). Create a simple scope map (diagram + table) listing IP ranges, VLANs, firewall interfaces, cloud VPCs/subnets, and third-party connections. This becomes your monitoring baseline and audit evidence.
Step 3 — Deploy flow collection and packet capture
Step 4 — Deploy deep inspection where needed
Enable NetFlow/IPFIX (or sFlow) on routers and firewalls to a central collector (example: export to 10.10.10.5:2055). For richer telemetry, deploy Zeek or Suricata on the network or on cloud instances to produce connection/session logs and IDS events. For the highest-risk egress points (VPN, data transfer servers), enable selective packet capture (pcap) or Arkime indexing. Where policy allows, implement TLS inspection at the NGFW or proxy for C2/exfil detection—document privacy considerations and selective bypasses for personal traffic.
Step 5 — Centralize logs and correlate
Step 6 — Create detection rules and baselines
Ship flow, proxy, IDS, firewall, DNS, and host logs into a SIEM (Splunk, Elastic, or a managed solution). Normalize fields (src_ip, dst_ip, bytes, protocol, domain, user). Build detection rules such as: large outbound volume (e.g., >1 GB within 10 minutes from a workstation), sudden spike in DNS TXT responses, DNS requests to newly seen domains, or outbound connections to known malicious IPs (feed with threat intel). Establish baselines per subnet/user and use anomaly detection to reduce false positives. Document rule logic and tuning steps in your evidence pack.
Step 7 — Alerting, triage, and response integration
Step 8 — Retention, reporting, and continuous improvement
Configure alerting to notify the SOC or designated staff via ticketing (Jira, ServiceNow) and ensure playbooks map alerts to triage steps (contain, collect artifacts, escalate). Retain flow and relevant logs per organizational risk—practical small business guidance: 90 days hot in SIEM, 1 year archived in cloud storage, and 3–7 years for legal/contractual obligations if required (adjust per contract). Schedule quarterly tuning, monthly dashboard reviews, and update the POA&M for any gaps found during tests or audits.
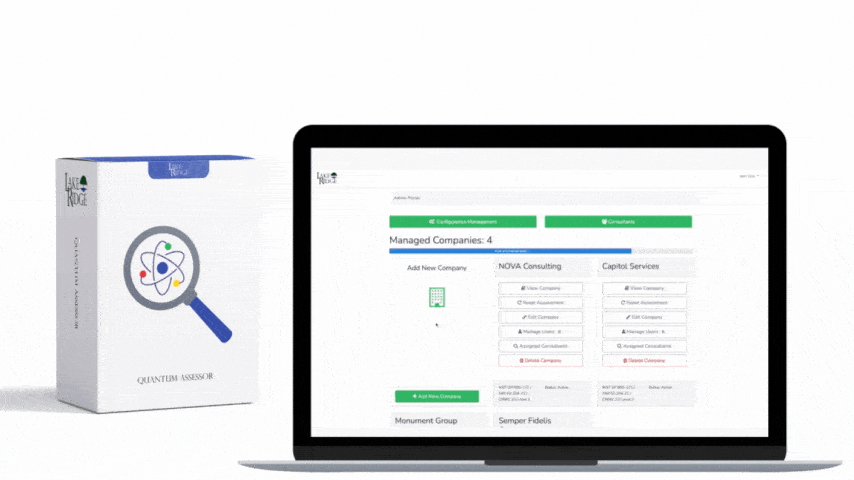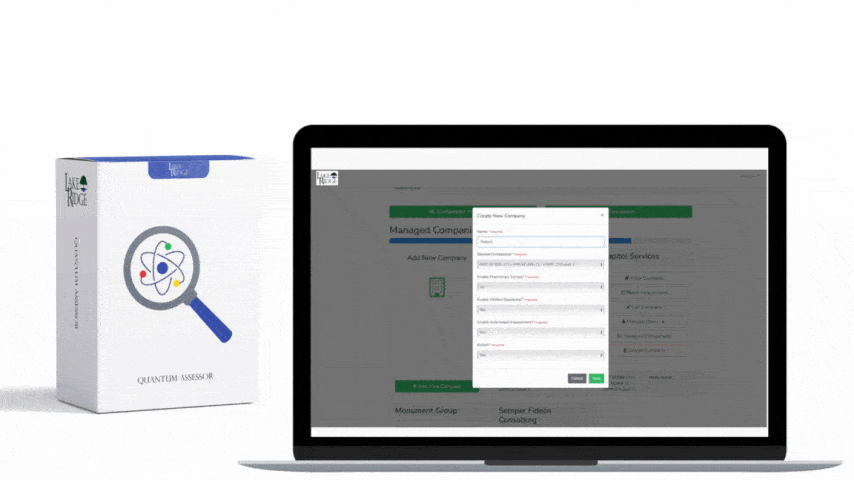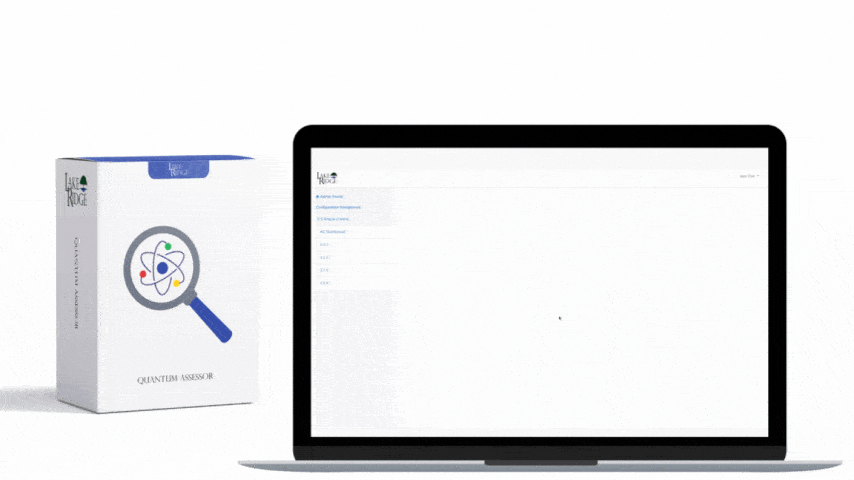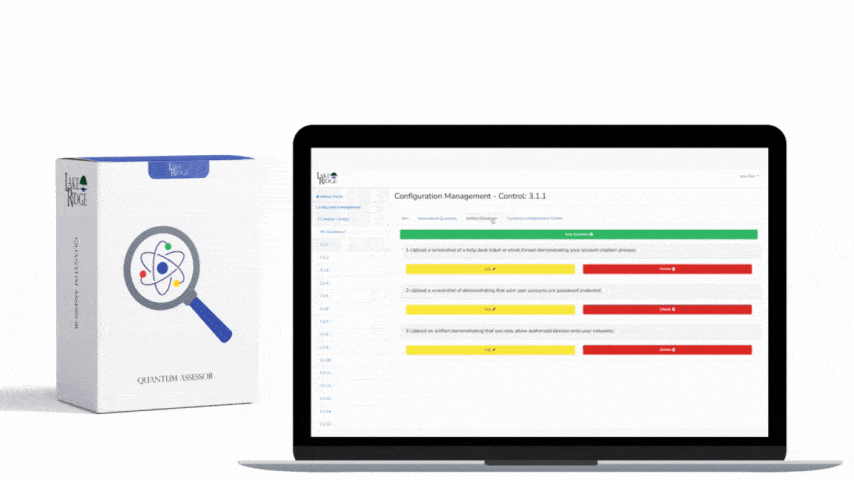
Implementation specifics for Compliance Framework
For Compliance Framework alignment, map each artifact to evidence: scope diagrams (policy), flow export configs (device screenshots or config snippets), SIEM rule exports, sample incident tickets, retention policies, and training records. Use the control language of SI.L2-3.14.6 in your System Security Plan (SSP) with traceability to the implemented technical items: NetFlow enabled on edge routers (show config), VPC Flow Logs enabled for AWS (show CloudTrail/S3 delivery), and SIEM correlation rule IDs linked to incident response playbooks.
Real-world small business scenarios and technical details
Example A — 30-person defense subcontractor using AWS: enable VPC Flow Logs to S3, ship logs to Elastic with Beats, deploy a Suricata sensor on the public subnet, and enable GuardDuty for additional detection. Detection rule: alert when an instance uploads >500 MB/hour to an external IP not in the whitelist (AWS NAT instance traffic). Example B — On-premises office with pfSense and a single ISP: enable NetFlow on the ISP edge (if supported) or install flow exporter on the internal router, forward flows to a small ELK stack, then use threshold alerts (e.g., one workstation contacting >100 unique external IPs in 15 minutes). Practical settings: flow sampling 1:10 on heavy links, 1:1 on critical CUI links; use eBPF collectors (Cloud native) where available for granular host-network telemetry without heavy overhead.
Risks, compliance tips, and best practices
Not implementing this control increases risk of undetected data exfiltration, contractual penalties, loss of DFARS/CUI contracts, and erosion of customer trust. Best practices: start small (protect the CUI corridor first), automate retention and evidence collection, feed threat intelligence into blocking lists, maintain an exceptions register with compensating controls, and run quarterly exfiltration tabletop exercises. Keep documentation concise and auditable: list the devices that export flows, show proof of SIEM ingestion, and retain 2–3 representative alerts with their triage outcome as evidence.
In summary, treating SI.L2-3.14.6 as an operational program—scope, collect, detect, respond, and document—lets small businesses meet NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 obligations without overspending: enable flow and session logging at perimeter and cloud choke points, centralize telemetry, tune detection rules to reduce noise, integrate alerts into your incident response, and keep a clear map from configuration artifacts to control statements in your SSP and POA&M.