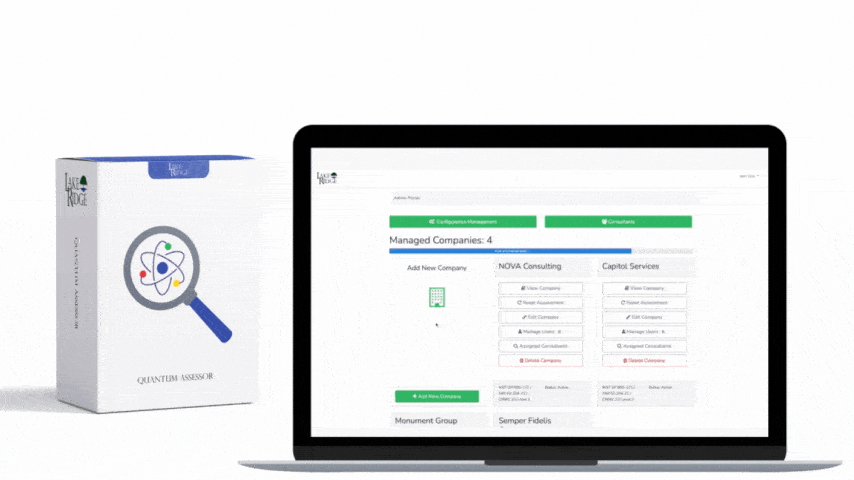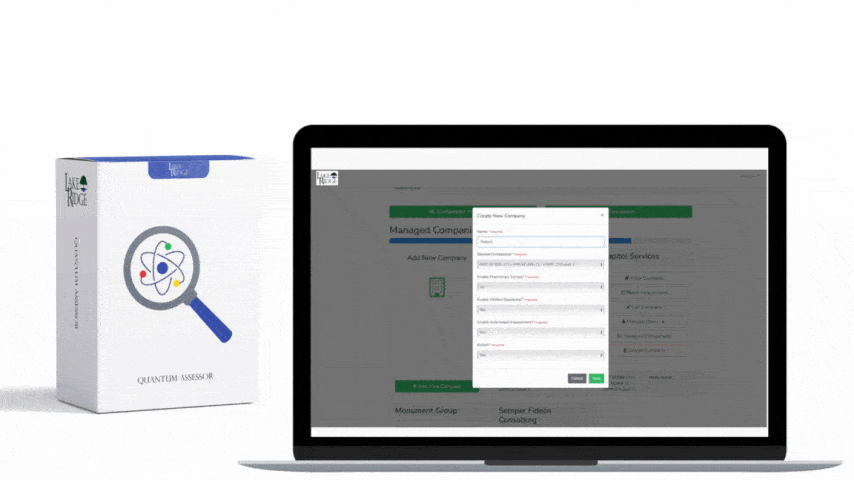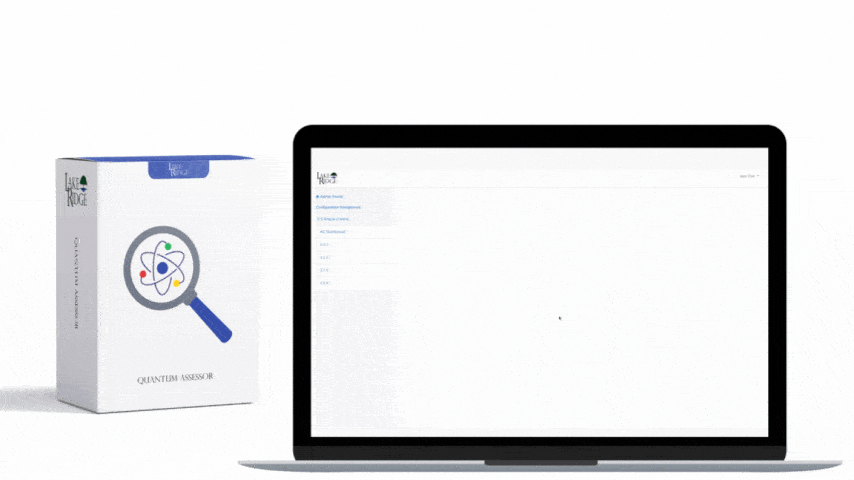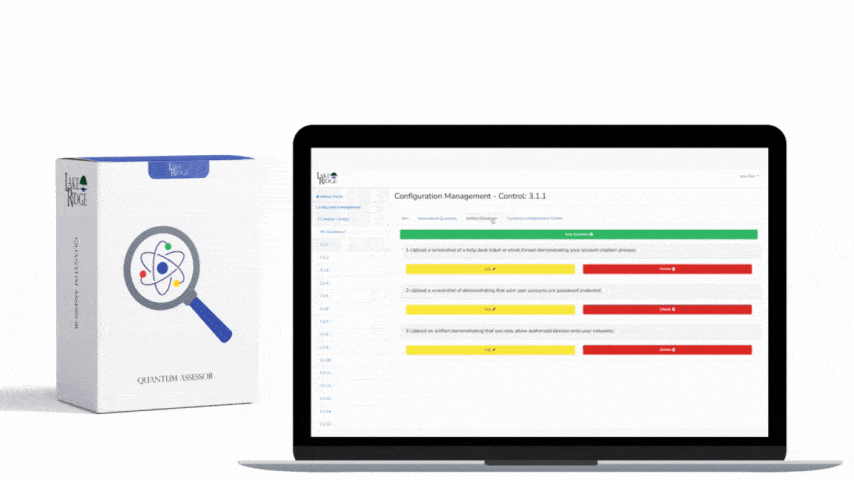
NIST SP 800-171 Rev.2 and CMMC 2.0 Level 2 require organizations to monitor system security alerts and advisories and take action (SI.L2-3.14.3) — implementing a repeatable SIEM-based workflow is the most practical way for a small business to meet that requirement, demonstrate evidence to assessors, and reduce the risk of compromise of Controlled Unclassified Information (CUI).
What SI.L2-3.14.3 means in operational terms
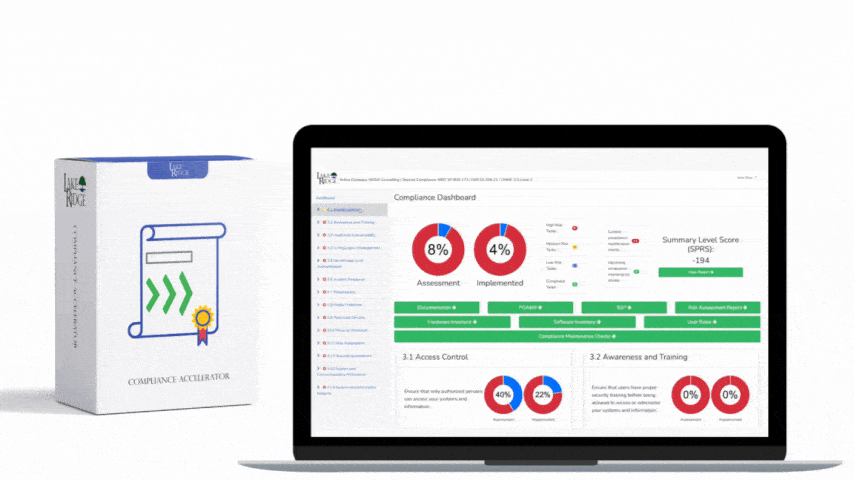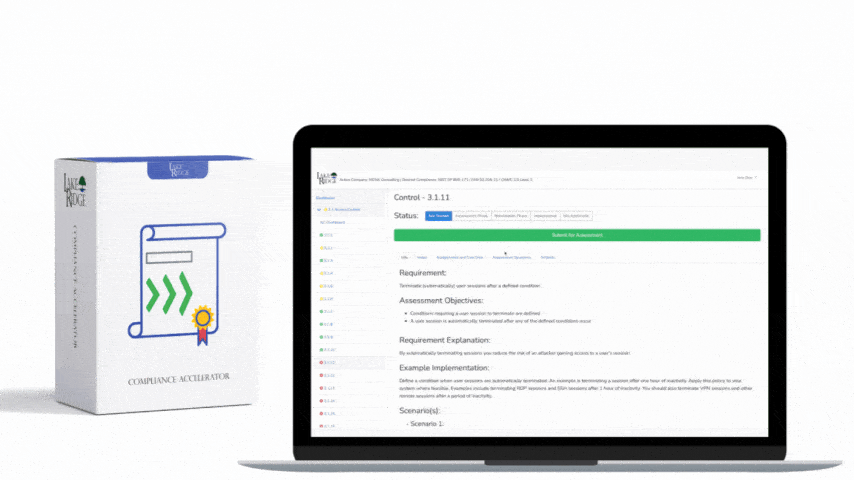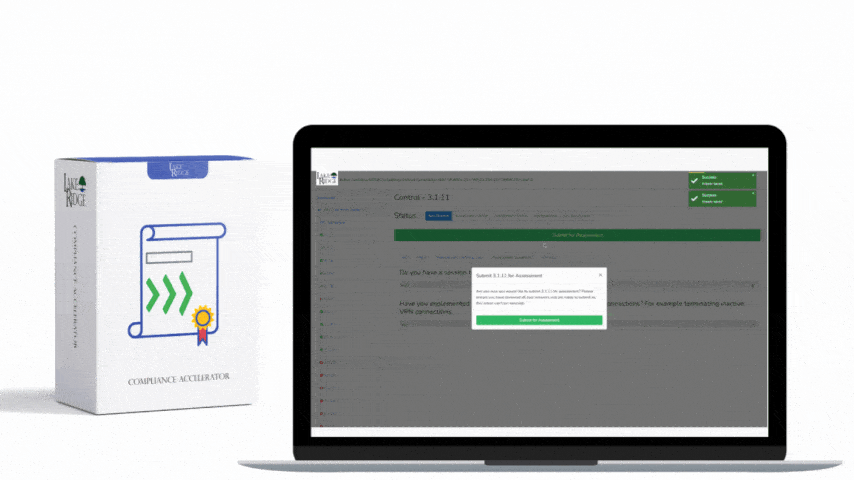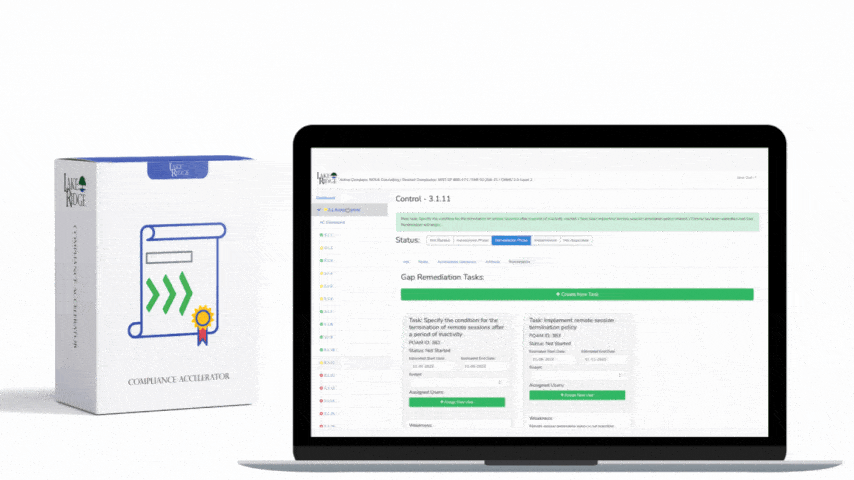
At its core, SI.L2-3.14.3 expects you to have an operational capability to receive security advisories (vendor PSIRTs, CISA KEV, NVD/CVE updates), monitor security alerts from your systems, and act on them in a documented, timely way. For a NIST SP 800-171 / CMMC Level 2 implementation that maps to this requirement, "act" means triage, prioritize (by criticality/CUI exposure), remediate or mitigate, and record the decisions and outcomes. Your SIEM becomes the central nervous system: ingest advisories and telemetry, correlate events, trigger playbooks, and provide auditable artifacts (alerts, tickets, timelines, remediation evidence).
Designing an SIEM-based workflow
Data sources: what to collect and why
Start with a prioritized list of data sources relevant to CUI and the small business environment: Windows security logs (Event IDs 4624/4625, 4688 process creation), Sysmon (event 1/3/11), Linux auth and sudo logs, EDR telemetry (process, file, network indicators), domain controller logs, firewalls/proxies (allow/deny and URL logs), VPN/SSO logs, and vulnerability scanner outputs (Nessus, OpenVAS, Qualys). Also ingest external advisory feeds: vendor PSIRTs, NVD CVE feeds, CISA Known Exploited Vulnerabilities (KEV), and trusted TI feeds. For small businesses with limited staff, focus first on EDR + domain controllers + perimeter logs and a daily CVE feed into the SIEM.
Ingestion, normalization and retention
Use lightweight collectors (Beats, NXLog, vendor agents) to send logs to your SIEM. Normalize fields using a common schema (ECS, CEF or your SIEM’s mapping) so detection rules can be generic across sources. Configure indexing/retention based on contract and assessment expectations — common practice is 90 days searchable hot storage and 12 months archived (compress/index as needed); however, confirm customer/contract retention requirements. Validate time synchronization across your estate (NTP) and capture metadata: hostname, asset owner, CUI tag, environment (prod/test). For practicality, small businesses can tier retention: 30–90 days in the SIEM for active investigations, 12 months exported to cheaper object storage for audit evidence.
Enrichment and threat intelligence
Enrich events with contextual data to prioritize actions: asset criticality (CUI servers first), vulnerability score (CVE + CVSS), external exploitability (CISA KEV or exploit-db flags), and MITRE ATT&CK technique mapping. Ingest TI via STIX/TAXII, or simpler RSS/CVE JSON feeds, and automatically tag events that reference known CVEs or indicators of compromise. Example: when a vulnerability scanner reports CVE-2025-1234 on a CUI server and the SIEM receives a vendor advisory marking it as "actively exploited," create a high-priority incident and attach remediation playbook automatically.
Detection rules, playbooks and automation
Rules and tuning
Create detection rules that map to real threats and CUI exposure. Example detection patterns: “5 failed logons (4625) across 3 hosts within 10 minutes” (possible credential stuffing), “Process created from unusual parent (Sysmon 1) followed by outbound connection to known malicious IP” or “New service registered remotely on a CUI host.” Write rules in your SIEM language (or Sigma rules) and include threshold, time window and asset-criticality filters to reduce false positives. Tuning is mandatory: track false positive rate and tune rules monthly until you reach acceptable signal-to-noise for your staffing level.
Playbooks, triage and ticketing
Automate first-line triage with playbooks: enrich the alert, check for active advisories/CVEs, query EDR for process artifacts, and determine scope. Integrate the SIEM with a ticketing system (ServiceNow, Jira, or a lightweight tracker like Trello) so every high/critical alert creates a ticket with required fields: timeline, affected assets, owner, mitigation steps, and SLA. For small businesses without SOAR, use scripted automations (Python/PowerShell) triggered by the SIEM webhook to collect artifacts and populate the ticket. Define SLAs that meet CMMC expectations — e.g., acknowledge within 2 hours for critical alerts and remediate or mitigate within 72 hours unless a documented extension is approved.
Operationalizing for compliance and auditability
Document each incident as evidence for assessors: SIEM alert exports (CSV/PDF), playbook runbooks, ticket IDs linking alert to remediation, patch/rollback records, and post-incident reviews. Maintain metrics and reports: time-to-detect, time-to-acknowledge, time-to-remediate, and percent of alerts closed within SLA. Regularly validate your SIEM pipeline by running tabletop exercises and scheduled adversary emulations (even simple tests like a controlled account lockout or simulated phishing follow-up) and capture the SIEM’s detection and the workflow timestamps as artifacts.
For a small business example: deploy Elastic Stack + Wazuh or Microsoft Sentinel if using Azure credits. In a 25-person org, you might start with EDR + domain controller logs forwarded to Elastic on a modest VM, subscribe to the NVD and CISA feeds, and set up 10 prioritized detections. Use a managed MSSP for 24/7 coverage if you can’t staff SOC functions; still require that the MSSP provide the ticketing artifacts and raw alert exports so you retain evidence for CMMC assessments.
The risk of not implementing SI.L2-3.14.3 is real: missed advisories and untriaged alerts can lead to exploitation of known vulnerabilities, lateral movement, exfiltration of CUI, contract loss, and failed CMMC assessments. From a business perspective, non-compliance can cause lost DoD contracts and reputational harm. From a technical perspective, without a structured SIEM workflow you will lack the timeline evidence assessors need to verify you acted on alerts and advisories.
Summary — build a prioritized, documented SIEM workflow that ingests advisories and telemetry, enriches and correlates events, automates triage and ticketing, and retains auditable artifacts. Start small: identify critical assets holding CUI, collect high-value logs, subscribe to CVE/CISA feeds, implement a handful of tuned detections, and formalize playbooks and SLAs. Whether you run an in-house Elastic/Wazuh stack, use Microsoft Sentinel, or rely on an MSSP, the goal is the same: demonstrable, repeatable action on security alerts and advisories to meet NIST SP 800-171 Rev.2 / CMMC 2.0 SI.L2-3.14.3 and to reduce real-world risk.