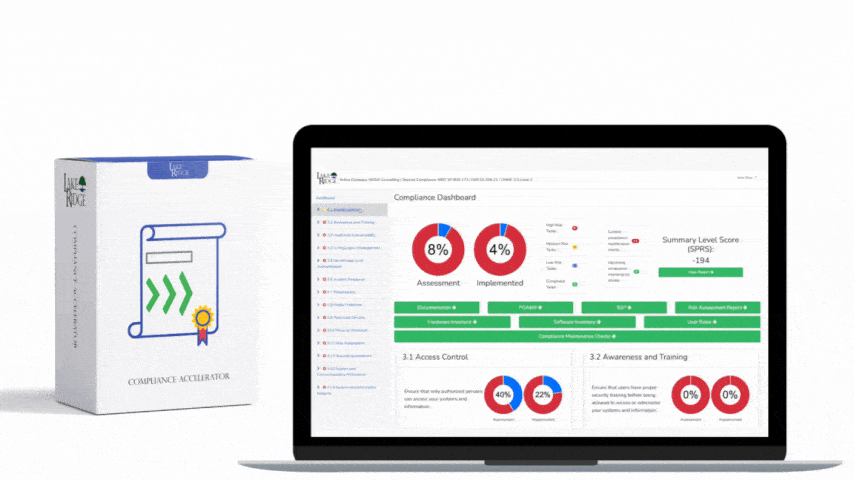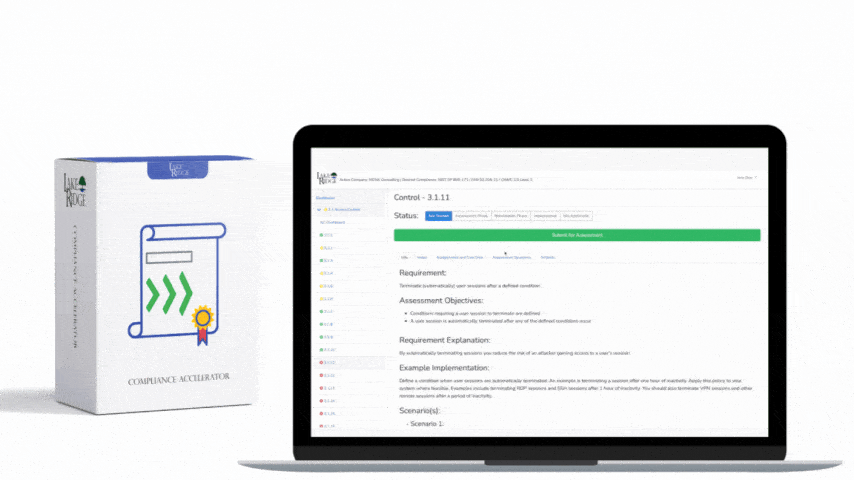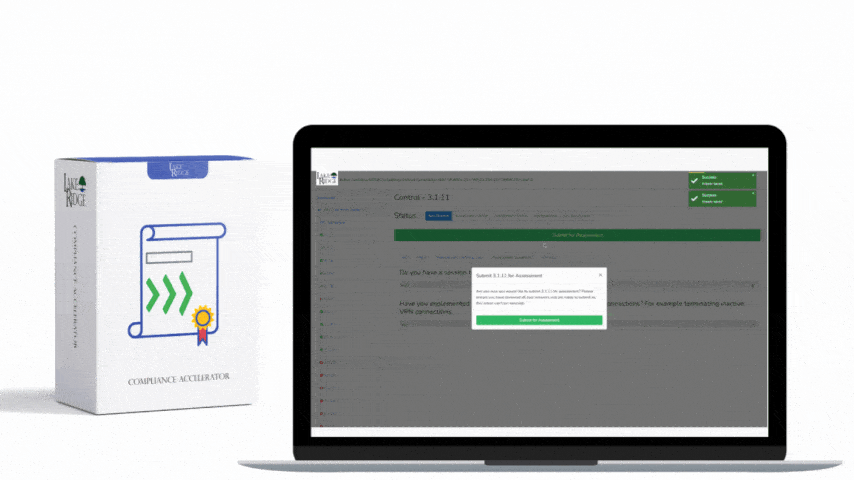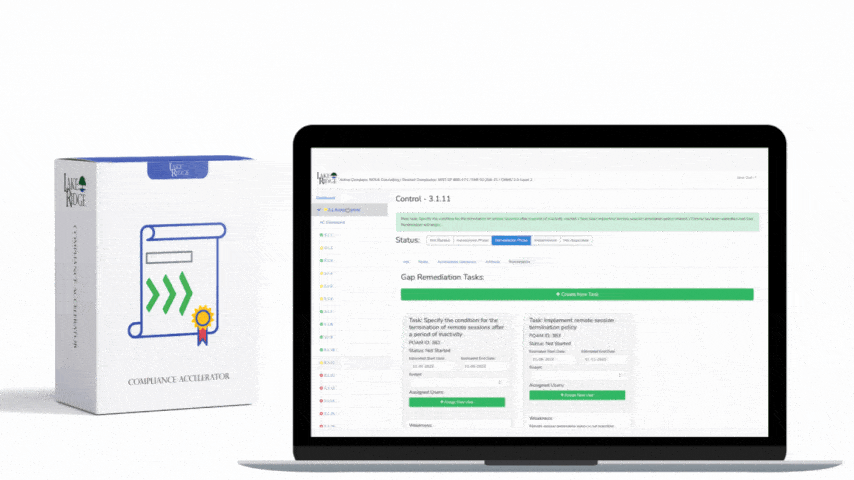
ECC 2-13-3 requires organizations to detect, alert on, and respond to security incidents and threats in a timely and auditable way — this post walks through a practical, small-business-friendly approach to configuring SIEM ingestion, detection rules, and alerting so you can meet incident and threat management requirements under the Compliance Framework.
Practical implementation steps for Compliance Framework alignment
1) Inventory log sources and prioritize by risk
Begin by mapping the Compliance Framework control to specific telemetry: identity/authentication (Azure AD/Office 365/Okta), endpoints (EDR like CrowdStrike, Defender, or Wazuh agents), perimeter devices (firewalls, VPN, proxies), cloud audit logs (AWS CloudTrail, Azure Activity Logs), and key applications (RMM, HR/payroll, CRM). For a small business (25–200 users), prioritize: identity logs, EDR process/alert events, firewall/SaaS egress logs, and Office 365 mailbox audit logs. Produce a "monitoring matrix" that lists each control requirement, the log source(s) that provide coverage, the collection method (agent, syslog, API), and retention SLA.
2) Configure reliable collection, normalization, and retention
Use secure transport (syslog over TLS or agent-to-SIEM TLS) and standard parsers (CEF/LEEF or JSON schemas). Ensure NTP is enabled across assets to avoid time drift in correlation. For Compliance Framework evidence, retain normalized logs for the timeframe required by your policy — a common practical baseline is 90 days for active SIEM indexes and 1 year in cold storage (S3/Blob with object-lock/WORM if required). Implement integrity checks (hashing) and role-based access to the log store so auditors can demonstrate tamper evidence.
Designing detection rules and correlation logic
3) Build prioritized detection use cases and sample rules
Create clear use cases mapped to the control (e.g., account compromise, privilege escalation, lateral movement, data exfil). Start with a small set of high-fidelity detections to avoid alert fatigue. Example rules with actionable parameters for small business environments:
- Failed-auth brute force: alert when an external IP generates >= 10 failed auth attempts across any accounts within 5 minutes. (Sources: firewall + auth logs).
- New privileged account: alert on Windows Security event ID 4720/4728 or Azure AD role assignment to privileged group within 10 minutes of creation.
- EDR + network correlation: if EDR flags a suspicious PowerShell spawn AND the same host initiates an outbound connection to a rare external IP within 15 minutes → HIGH alert.
- Data exfil candidate: if a single endpoint transfers > 500 MB to an external IP not seen in the last 90 days, or to cloud storage (S3/GDrive) outside sanctioned tenant → medium/high alert.
4) Rule tuning and false-positive mitigation
Implement allowlists (trusted IPs, known management services), suppression windows for maintenance periods, and baselining to learn normal behavior. Use contextual enrichment — AD group membership, asset owner, risk score, geoIP and threat intel lookups — to increase precision. For example, suppress failed-auth alerts from known Office 365 Health IPs, and enrich alerts with user location and last login time to speed triage.
Alerting, triage playbooks, and automation
5) Map alert severity to response playbooks and SLAs
Define clear severity levels and associated actions to meet Compliance Framework incident management expectations. For a small business, practical SLA targets could be: MTTD (mean time to detect) < 60 minutes for HIGH, MTTR (containment) < 4 hours for HIGH. Create short, specific playbooks per alert type: who to notify (on-call, CISO/owner), immediate containment (isolate host via EDR, block IP on firewall), evidence capture (preserve memory, take full disk image only if warranted), and ticket creation in your ITSM (Jira/ServiceNow/Zendesk). Embed playbooks into SIEM/SOAR so initial enrichment and ticket creation are automated.
6) Integrate with EDR, SOAR, and ticketing
Enable two-way integrations: SIEM receives EDR events and can call EDR APIs to quarantine or kill processes; SOAR automates enrichment (WHOIS, VT, ASN) and runs scripted containment steps. For small shops using managed services, ensure the MSSP has access to the same playbooks and that notification channels (SMS, email, Slack) are tested. Store every alert and response as auditable evidence tied back to the Compliance Framework control.
Testing, documentation, and continuous improvement
7) Test detections, run tabletop exercises, and tune quarterly
Validate rules with realistic tests: simulated brute-force, creating test admin accounts, controlled file uploads to external storage, and EDR test alerts (e.g., use benign PowerShell scripts flagged by EDR). Run quarterly tabletop exercises to validate escalation, communication, and evidence collection. Keep a change log for rule updates to show auditors continuous improvement and control efficacy.
Risks of not implementing ECC 2-13-3 aligned SIEM and alerting
Failing to implement these detection and alerting controls increases the risk of prolonged undetected compromise, data exfiltration, regulatory fines, and reputational damage — especially for small businesses that may lack multiple layers of detection. Without proper collection and playbooks, incidents become slow and costly to investigate, and the organization cannot demonstrate timely detection and response to auditors under the Compliance Framework.
Summary: To meet ECC 2-13-3 incident and threat management requirements, build a prioritized log inventory, configure secure collection and normalization, implement a focused set of high-fidelity detection rules with contextual enrichment, map alerts to response playbooks with clear SLAs, integrate SIEM with EDR/SOAR/ticketing, and validate continuously through tests and tabletop exercises — these practical steps will reduce detection time, lower false positives, and produce auditable evidence for compliance.