This post gives a practical, compliance-focused 5-step Business Continuity Management (BCM) plan you can implement today to satisfy Essential Cybersecurity Controls (ECC – 2 : 2024), Control 3-1-2, with clear actions, technical details, and small-business examples.
Why Control 3-1-2 matters for your Compliance Framework
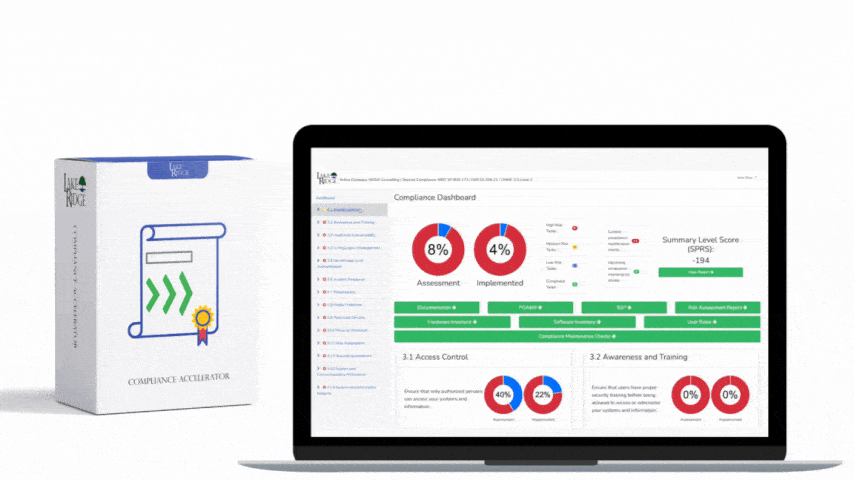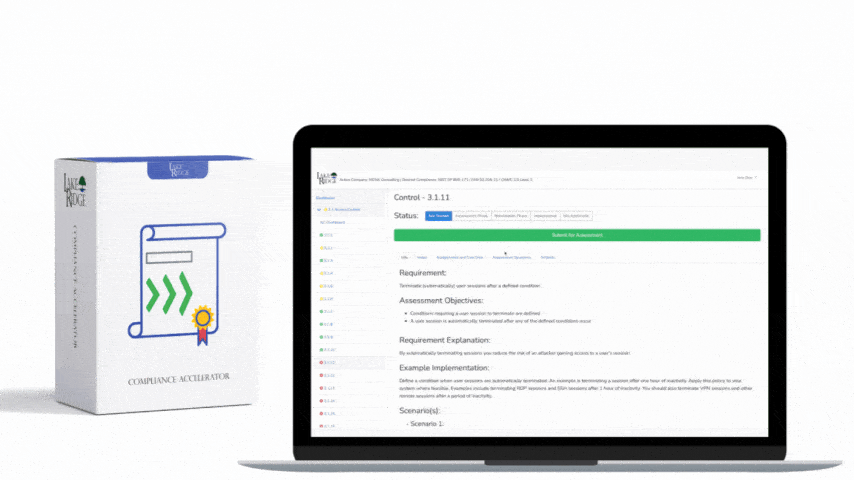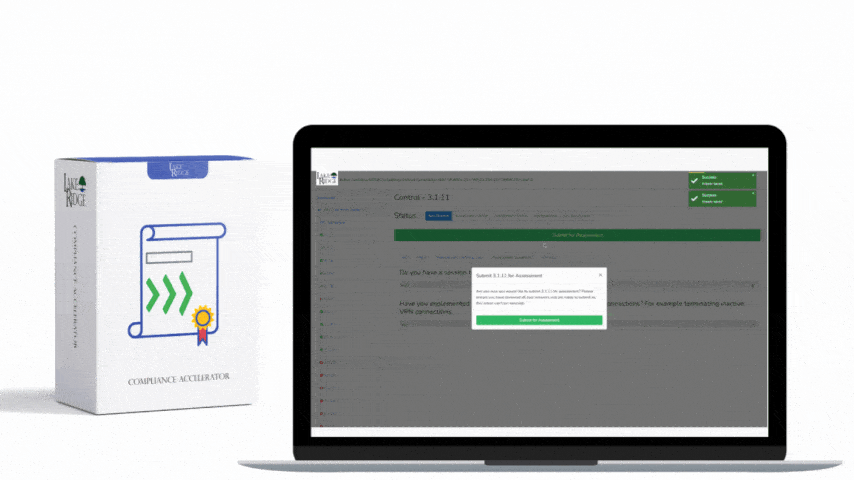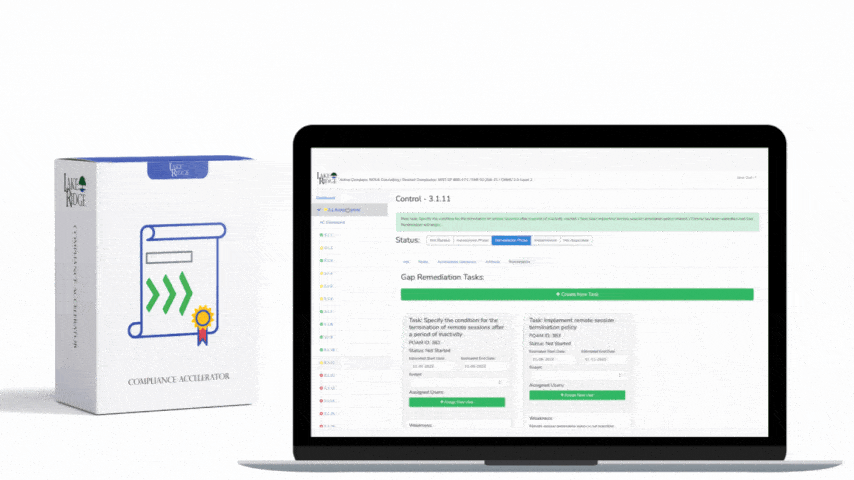
Control 3-1-2 in ECC‑2:2024 requires a documented, tested business continuity capability proportional to business risk and critical-asset impact. For a Compliance Framework implementation this means you must produce evidence — policies, risk analysis, procedures, test results, and senior management approval — that demonstrate your ability to restore critical services within defined Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs).
The 5-step BCM plan mapped to Control 3-1-2
Below is a prescriptive five-step plan you can use as the basis of your BCM documentation. Each step includes specific implementation notes for the Compliance Framework, technical controls to deploy, and evidence you should retain for auditors.
Step 1 — Identify & prioritize (Business Impact Analysis)
Action: Run a Business Impact Analysis (BIA) to catalogue processes, dependencies, and maximum tolerable period of disruption (MTPD). For each process list required systems, attendees, third-party services, data classification, and legal/regulatory obligations.
Technical specifics: Map each critical service to infrastructure components (e.g., “ecommerce website -> web server cluster (2 nodes), DB (Postgres RDS Multi-AZ), payment gateway (third‑party), DNS”). Assign RTO and RPO — example: payment processing RTO = 1 hour, RPO = 15 minutes; accounting server RTO = 8 hours, RPO = 24 hours.
Evidence for Compliance Framework: BIA spreadsheet with service owners, signed MTPD/RTO/RPO by management, asset inventory exported from CMDB or simple CSV for small businesses.
Step 2 — Define recovery strategy and technical controls
Action: Select cost-effective strategies that map to your RTO/RPO targets. Options include cloud region failover, active-passive replication, DNS failover, snapshots, and offline backups. For small businesses prefer managed services that simplify proofs (e.g., AWS RDS Multi-AZ, Azure Site Recovery, or vendor backup solutions like Veeam/Backblaze).
Technical specifics & examples:
- Database: Implement WAL shipping or managed DB multi‑AZ; daily logical backups plus transaction log backups every 15 minutes for RPO=15min.
- Files/Config: Use versioned object storage (S3 with versioning + lifecycle to Glacier), encrypt with AES‑256, and replicate to a second region.
- Systems: Keep bootable VM images or IaC (Terraform) templates, and store runbooks in a version-controlled repo (Git) with tagged releases.
- Access: Create “break glass” recovery accounts protected by MFA and stored in an encrypted secrets manager (HashiCorp Vault or cloud KMS).
Evidence: Architecture diagrams, backup schedules, encryption key policy, replication configuration screenshots, and cost analysis tying strategy to chosen RTO/RPO.
Step 3 — Build the plan & write runbooks
Action: Convert strategy into an executable Business Continuity Plan and specific runbooks. Each runbook should include activation criteria (e.g., “Service unavailable >15 minutes or SLA breach”), step-by-step recovery steps, roles/responsibilities, communication templates, and escalation contacts.
Practical runbook details:
- Trigger example: If primary DB fails and cannot accept writes within 10 minutes, promote replica and update DNS with TTL=60s.
- Command-level steps: SSH to bastion, run promote-replica.sh, validate service health via /health endpoint, run smoke tests (curl status checks), and confirm payment gateway connectivity.
- Logging & evidence capture: Take screenshots, export CloudWatch/CloudTrail logs, and attach recovery timeline to the incident ticket.
Compliance artifacts: Signed runbooks, version-controlled backup of runbooks, and a location where the plan is stored (encrypted S3 bucket + offline printed copy in a locked safe if required).
Step 4 — Test, train, and record
Action: Schedule and execute regular tests — tabletop exercises quarterly and live recovery tests annually (or more frequently depending on risk). Tests should be realistic but scoped to avoid business disruption (e.g., use a staging environment or service window).
Testing specifics:
- Tabletop: Walkthrough RTO/RPO scenarios with execs and service owners; record decisions and gaps.
- Full failover: Simulate region outage and failover using IaC to bring up services in a secondary region, verify data integrity, and confirm customer workflows.
- Metrics to capture: Time to detection, time to recover (MTTR), percentage of critical workflows validated, and test success rate.
Compliance evidence: Test plans, attendance lists, test result reports, logs showing time stamps, post-mortem with action items, and proof that corrective actions were implemented (change tickets).
Step 5 — Maintain, improve, and govern
Action: Integrate BCM into your Compliance Framework governance cycle: annual plan review, change control integration, and continuous monitoring. Ensure senior management signs off on the plan and budget for improvements identified in tests.
Practical governance controls:
- Link BCM changes to configuration management and vulnerability remediation processes.
- Automate monitoring and alerting (Prometheus + Alertmanager, CloudWatch) and define SLAs for on-call rotation during recovery events.
- Maintain an audit trail: commit runbook changes to Git, store signed PDFs of the plan, and keep test records for the audit retention period specified by your Compliance Framework.
Real-world small-business scenarios
Scenario 1 — E‑commerce shop: A small retailer uses a hosted CMS + managed DB. Implement nightly backups to S3, enable multi-AZ DB replication, and create a runbook to point DNS to a cached storefront in CloudFront while the origin DB is being recovered. Test by failing the primary DB in a staging window and measuring time to restore shopping cart functionality.
Scenario 2 — Local accounting firm: Their critical asset is an on-premises accounting server. Implement encrypted incremental backups to cloud (Backblaze B2 or S3-compatible), maintain a VM image exported weekly, and have a documented plan to spin up the VM in a cloud provider within the RTO. Keep client notification templates and regulatory reporting steps in the runbook.
Risks of not implementing Control 3-1-2
Failing to implement a BCM aligned to Control 3-1-2 exposes you to extended downtime, data loss, regulatory non‑compliance fines, contract breaches with customers, and reputational harm. For small businesses, a single prolonged outage—especially one affecting payments or client data—can be unrecoverable. Lack of documented tests and evidence also almost certainly means failing a Compliance Framework audit.
Compliance tips and best practices
Practical tips:
- Start small: document the top 5 critical processes first and expand.
- Use managed services to reduce operational burden and provide built-in HA features that are easy to document.
- Keep runbooks short, actionable, and command-level. Use checkboxes and timestamps during tests.
- Protect recovery credentials using an encrypted secrets manager and apply least-privilege access.
- Log and preserve all test evidence—screenshots, timestamps, and signed post-test reports—to satisfy auditors.
Summary: By following this five-step BCM plan—Identify & prioritize, Define strategies, Build runbooks, Test & train, and Maintain & govern—you create a verifiable, auditable program that satisfies ECC‑2:2024 Control 3-1-2. Implement technical controls (replication, versioned backups, encrypted storage, break-glass accounts), run realistic tests, and keep clear evidence. For small businesses, prioritize critical services and leverage managed offerings to achieve compliance efficiently while minimizing cost and complexity.