Control 2-1-2 of the ECC-2:2024 framework's Essential Cybersecurity Controls (ECC – 2 : 2024) requires organizations to implement automated discovery and continuous monitoring for asset management so that every hardware, software and cloud resource is identified, inventoried, and tracked throughout its lifecycle; this post provides practical, technical steps and real-world examples to satisfy that requirement and produce audit-ready evidence.
What Control 2-1-2 Requires (in practice)
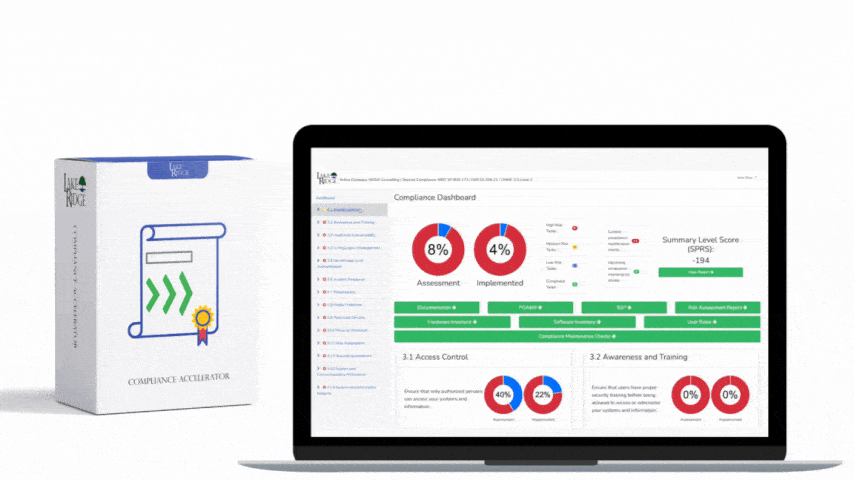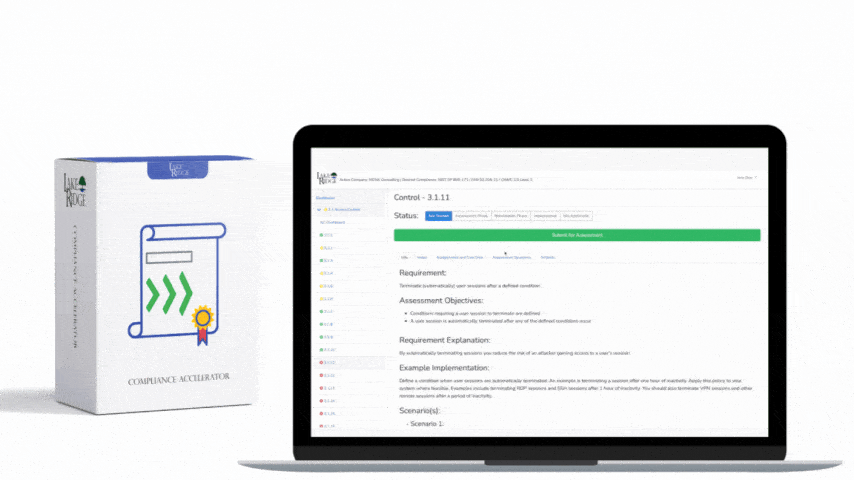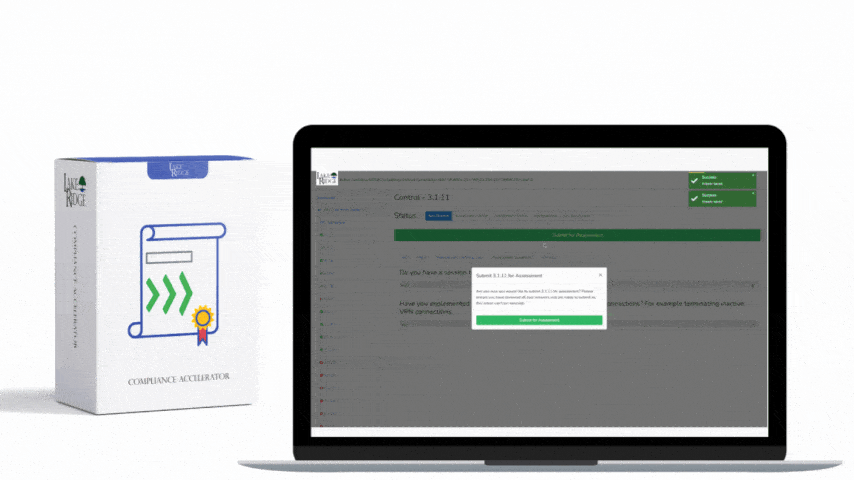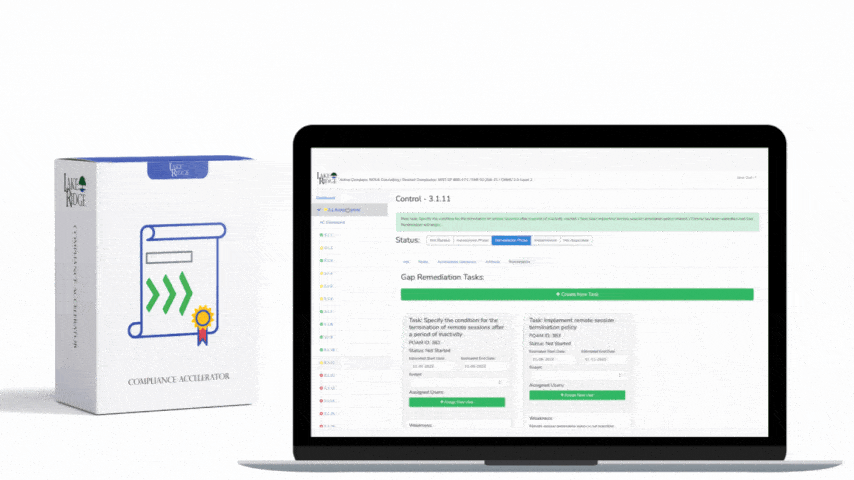
At a practical level, ECC-2:2024 Control 2-1-2 expects an automated process that: (1) discovers new and changed assets across networks and cloud environments, (2) continuously monitors those assets for configuration drift, patch status, installed software and connectivity, and (3) feeds that information into a single authoritative inventory (CMDB or asset registry) with timestamps, owners and classification metadata. Acceptable evidence includes discovery logs, reconciliation reports, monitoring alerts and a demonstrable link between the inventory and remediation/ticketing actions.
Practical Implementation Steps
Step 1 — Select discovery technologies and methods
Choose a combination of agent-based and agentless discovery to cover diverse environments. For on-premises Windows and Linux endpoints, deploy lightweight agents (e.g., Wazuh/Elastic Agent, Microsoft Defender for Endpoint) to capture installed software, running services, and local configuration. Use agentless techniques (Nmap, Nessus, or cloud-provider APIs) for network devices, printers, and unmanaged endpoints via SNMP/ICMP/SSH/WinRM. In cloud-first environments, enable AWS Config, Azure Resource Graph and GCP Asset Inventory to discover cloud resources via APIs. For small businesses with limited budget, combine scheduled Nmap scans, WinRM/SSH queries, and cloud API pulls to create a baseline, then add agents incrementally for critical systems.
Step 2 — Integrate discovery with an authoritative inventory (CMDB)
Automate ingestion of discovery data into your CMDB or asset registry using connectors or the product API (ServiceNow, GLPI, or a simple database + automation pipeline). Make sure each asset record contains: unique identifier (MAC/UUID/instance ID), owner or owner group, classification (prod/test/dev), location, software inventory, last-seen timestamp and risk tag. Implement reconciliation rules to merge duplicates (e.g., same MAC from multiple scans) and to mark stale records (last-seen > X days). For small businesses, a lightweight CMDB (Postgres + a simple web UI or open-source OCS Inventory / FusionInventory) with a scheduled ETL (Python scripts using APIs) is sufficient to demonstrate compliance.
Step 3 — Configure continuous monitoring and alerting
Define monitoring frequency based on asset criticality: high-value servers and cloud instances should be monitored in near real-time (via agent telemetry or cloud event streaming), while workstations can be scanned daily. Integrate vulnerability scanners (Qualys, Nessus, or OpenVAS) and a SIEM (Splunk, Elastic, or Wazuh) to centralize logs and produce alerts on new/unapproved software, missing patches, configuration drift, or previously unknown devices. Automate ticket creation in your ITSM (Jira, ServiceNow, or a simple webhook) for any asset that falls out of policy. For small teams, configure thresholds conservatively (e.g., auto-ticket anything critical or high-risk, aggregate low/medium for weekly review) to avoid alert fatigue.
Small-Business Example: 50-seat company with hybrid cloud
Example implementation: a 50-employee company uses Office 365, an AWS account for applications and a mix of Windows laptops and Linux servers. Practical steps: enable AWS Config and AWS CloudTrail to capture cloud assets and changes; deploy Elastic Agents on the 10 production servers and enroll laptops via Microsoft Intune to capture telemetry; run weekly Nmap scans of the office network to catch unmanaged IoT and rogue devices; ingest all data into an Elastic Stack instance and a simple PostgreSQL CMDB that receives periodic API pushes from discovery tools. Evidence for an audit would be scheduled discovery job logs (cron timestamps), CMDB entries with last-seen and owner fields, vulnerability scan reports, and tickets showing remediation actions taken.
Technical details and evidence you should produce
For ECC-2:2024 auditors, produce: automated discovery logs (timestamped, inclusive of scan parameters), CMDB export showing unique IDs and last-seen times, alerts and SIEM events tied to asset identifiers, change/reconciliation reports (showing when duplicate records were merged), and a remediation trail (ticket ID → remediation status → closure). Retain logs for the period specified by the ECC-2:2024 framework (document retention requirements in your policy), and digitally sign or hash inventory snapshots to prevent tampering. Use API-driven exports (JSON) to create immutable snapshots for quarterly audits.
Risks of not implementing automated discovery and continuous monitoring
Without automation you face shadow IT, unknown internet-exposed assets, delayed detection of vulnerable systems, and a weakened incident response capability — all of which increase the chance of malware outbreaks, ransomware, data loss and failed audits under the ECC-2:2024 framework. Small businesses are especially vulnerable: a single unmanaged device can provide attackers a foothold, and lack of evidence makes regulatory fines and insurance claims more likely after an incident.
Summary — implement Control 2-1-2 iteratively: start with automated discovery (cloud APIs + scheduled network scans), feed findings into an authoritative CMDB, add agents for critical systems, and configure continuous monitoring integrated with vulnerability scanning and ticketing. Provide auditors with time-stamped discovery logs, inventory snapshots and remediation records to demonstrate compliance with the ECC-2:2024 framework ECC – 2 : 2024 Control 2-1-2; doing so reduces risk, speeds incident response and creates a repeatable compliance posture for growth.