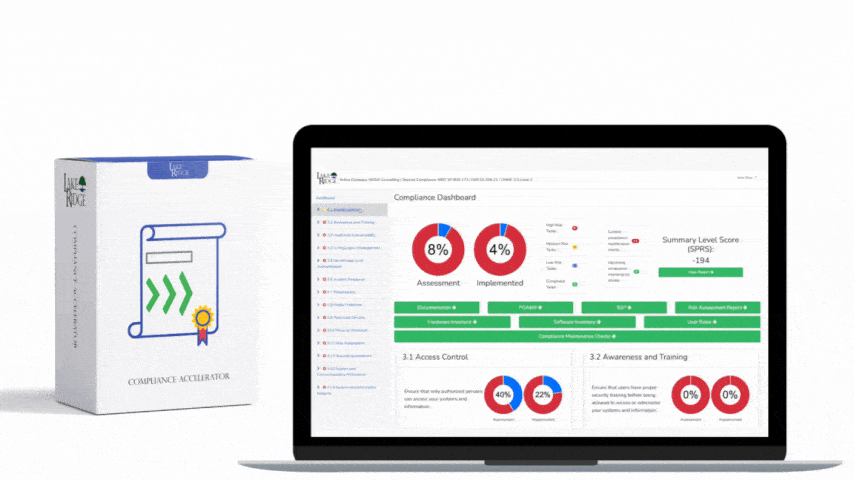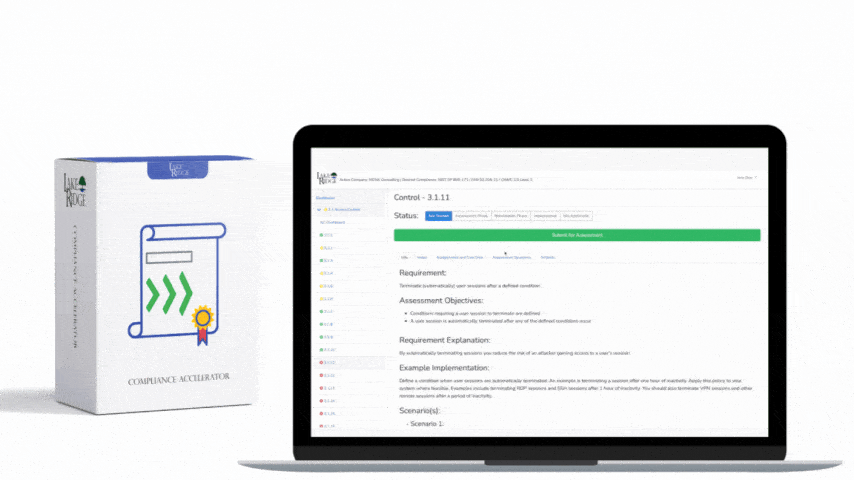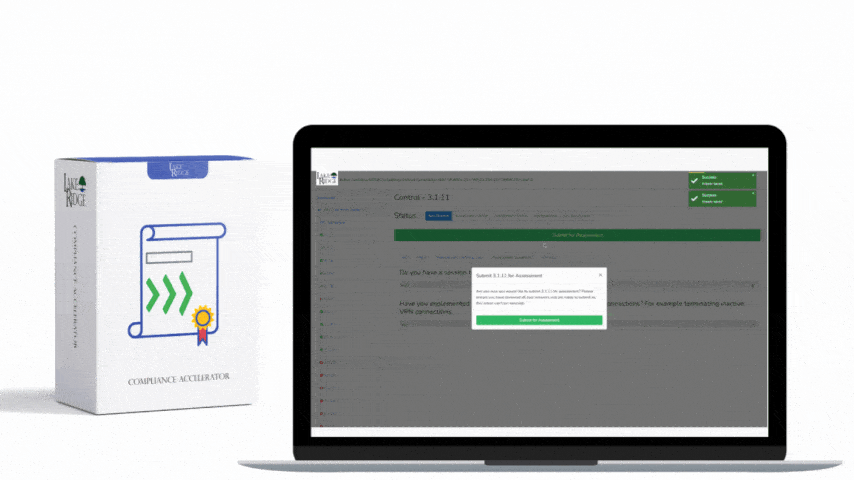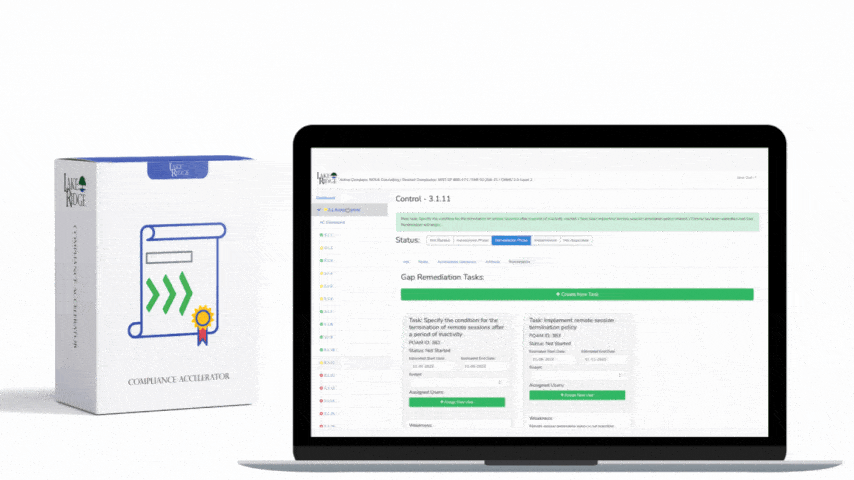
This post explains how to detect and alert on audit-log failures using native services in AWS, Azure, and GCP so you can meet the intent of NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 Control AU.L2-3.3.4 — i.e., ensure continuous audit capability and rapid notification when audit data stops being produced, ingested, or delivered.
Why this control matters
The control requires organizations to identify and respond when audit logging fails, because missing logs or pipeline failures break your ability to detect and investigate incidents — a critical capability for Controlled Unclassified Information (CUI) holders and for meeting CMMC Level 2. If logging stops, attackers can operate undetected, forensic timelines are lost, and you risk regulatory non‑compliance and contractual penalties.
High-level implementation strategy
Across cloud providers the same principles apply: (1) produce audit events (cloud provider control plane + resource logs), (2) ensure logs are exported/ingested into a central log store or SIEM, (3) create metrics that measure successful ingestion or event volume, (4) create alerts for anomalies such as pipeline errors, config changes that disable logging, or sustained zero/low event volume, and (5) harden and monitor the logging pipeline (encryption, retention, access controls). For compliance, document the detection logic, owners, escalation procedures, and test results.
AWS — practical steps (CloudTrail, CloudWatch, SNS)
1) Ensure CloudTrail is enabled organization-wide and delivering to an S3 bucket and optionally to CloudWatch Logs. 2) Monitor both control-plane CloudTrail and any resource logs you depend on (VPC Flow Logs, ELB, Lambda). 3) Use CloudWatch Logs "IncomingLogEvents" metric on the CloudTrail log group or create a CloudWatch Logs metric filter that counts events. 4) Create a CloudWatch alarm that triggers when IncomingLogEvents falls below an expected threshold (for example, less than 1 event in 15 minutes for small environments) or when you observe a CloudTrail configuration change event (CloudTrail StopLogging or DeleteTrail). 5) Send the alarm to an SNS topic with email/Slack/SMS subscriptions and to your on-call tool.
Example AWS CLI alarm (illustrative — replace ARNs and names):
aws cloudwatch put-metric-alarm \
--alarm-name "CloudTrail-Ingestion-Low" \
--metric-name IncomingLogEvents \
--namespace "AWS/Logs" \
--dimensions Name=LogGroupName,Value="/aws/cloudtrail/logs" \
--statistic Sum \
--period 900 \
--evaluation-periods 1 \
--threshold 1 \
--comparison-operator LessThanOrEqualToThreshold \
--alarm-actions arn:aws:sns:us-east-1:123456789012:LogAlertsAlso create EventBridge rules to detect specific management events that indicate logging changes, e.g., CloudTrail StopLogging, PutEventSelectors, PutBucketAcl (if S3 is used), and alert on those immediately.
Azure — practical steps (Activity Log, Diagnostic Settings, Log Analytics)
1) Configure Activity Logs and resource Diagnostic Settings to send platform and resource diagnostics to a Log Analytics workspace and to an archive (storage account) or Event Hub. 2) Create a Log Analytics scheduled query that counts audit / activity log events (for example, type = "Administrative" or a specific set of operations). 3) Create an Azure Monitor alert rule (scheduled query or metric) that fires when ingestion count is unexpectedly low (e.g., zero records in 5–15 minutes) or when there's an administrative operation that modifies Diagnostic Settings. 4) Protect diagnostic settings with Azure Policy and alert on policy noncompliance.
Example Kusto query for a scheduled alert (Log Analytics):
AzureActivity
| where TimeGenerated > ago(15m)
| where OperationNameValue == "Microsoft.Insights/diagnosticSettings/delete" or Category == "Administrative"
| summarize count()Create an Action Group to notify email/SMS/Teams/LogicApp for automated remediation.
GCP — practical steps (Cloud Audit Logs, Logging, Monitoring)
1) Ensure Cloud Audit Logs (admin/activity/data access as required) are enabled and exported to a logs sink (Cloud Storage, BigQuery, Pub/Sub) or to Cloud Logging buckets. 2) Create a logs-based metric in Cloud Logging that counts audit events (filter on logName: "cloudaudit.googleapis.com/activity" or methodName patterns). 3) Create a Monitoring alerting policy that triggers when the metric's value drops below an expected threshold over a window (e.g., 1 event per 10 minutes). 4) Also alert on sink deletion or permission changes to the logging sink service account, and on unexpected drops in "logging.googleapis.com/ingested_bytes".
Example gcloud to create a logs-based metric:
gcloud logging metrics create audit_events \
--description="Count of Cloud Audit Logs (admin/activity)" \
--log-filter='logName="projects/PROJECT_ID/logs/cloudaudit.googleapis.com%2Factivity"'Then use Cloud Monitoring to create an alerting policy that evaluates the metric and sends notifications to email/SMS/Cloud Pub/Sub.
Small business scenarios and real-world examples
Scenario A — 10-seat startup (low ops headcount): enable provider defaults (CloudTrail in AWS, Activity Log in Azure, Cloud Audit Logs in GCP) and route them to a single secure archive bucket or workspace. Create a simple "no-events" alarm that notifies two people via email and Slack; document owners and a 30-min SLA for acknowledgment. Scenario B — Small contractor handling CUI: enforce organization-wide CloudTrail with encryption via KMS, enable S3 object lock/retention for logs, create alarms for CloudTrail configuration changes and low ingestion, and integrate alerts with a ticketing system. Simulate outages quarterly by disabling a diagnostic setting in a test account to verify alerts and runbooks.
Compliance tips and best practices
- Use both positive (presence-count) and negative (explicit error events) checks: alarm on low/no events and on management events that disable logging. - Protect the logging pipeline: encrypt logs with customer-managed keys, restrict who can change diagnostic settings, and use immutable storage/retention where required. - Reduce alert fatigue: tune thresholds by environment (production will have more baseline events than dev), use suppression windows for expected maintenance, and route alerts to escalation tiers. - Document detection logic, owners, playbooks, and test results to demonstrate to auditors that AU.L2-3.3.4 is implemented and operational. - Automate remediation where safe (e.g., redeploy a diagnostic setting when deleted in a dev/test account) but keep human-in-the-loop for production changes.
Risk of not implementing this requirement
If you do not detect audit log failures, you lose the ability to investigate breaches and to demonstrate what happened — leading to longer dwell times for adversaries, missed data exfiltration, and inability to meet contractual and CUI protection obligations. From a compliance perspective, auditors will flag the lack of monitoring and alerting as a deficiency under NIST SP 800-171 AU controls and CMMC Level 2, potentially affecting your contract eligibility.
In summary, using native logging and monitoring features in AWS, Azure, and GCP you can implement robust detection of audit-log failures: create ingestion and configuration-change detectors, alert on low/absent event counts and on management events that disable logging, protect the pipeline, and document and test the solution. For small businesses the priority is to enable provider defaults, add a low‑noise "no‑events" alert, protect diagnostic settings, and run periodic tests — all of which satisfy the intent of AU.L2-3.3.4 and materially reduce compliance and security risk.