Requirement
Essential Cybersecurity Controls (ECC – 2 : 2024) - Control - 2-13-3 – The requirements for cybersecurity incidents and threat management must include at least the following:
Understanding the Requirement
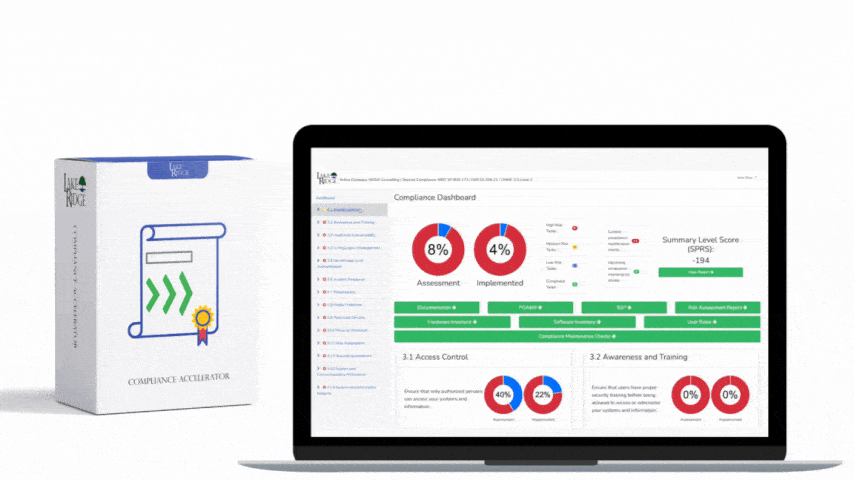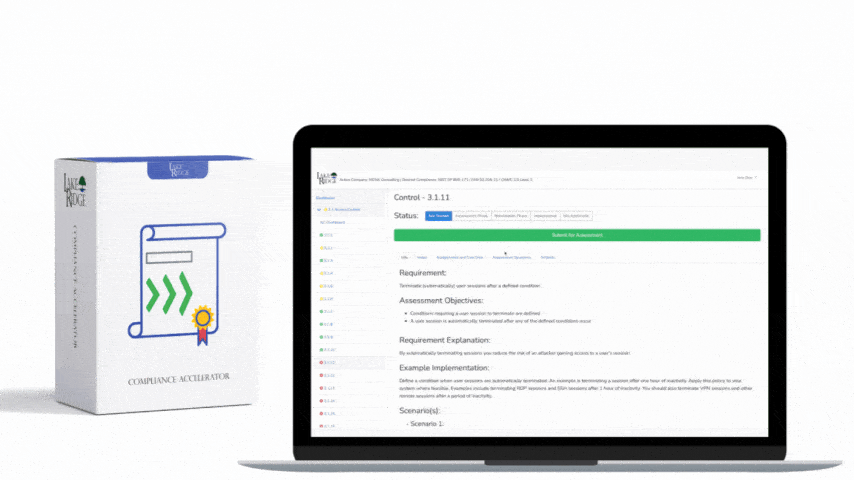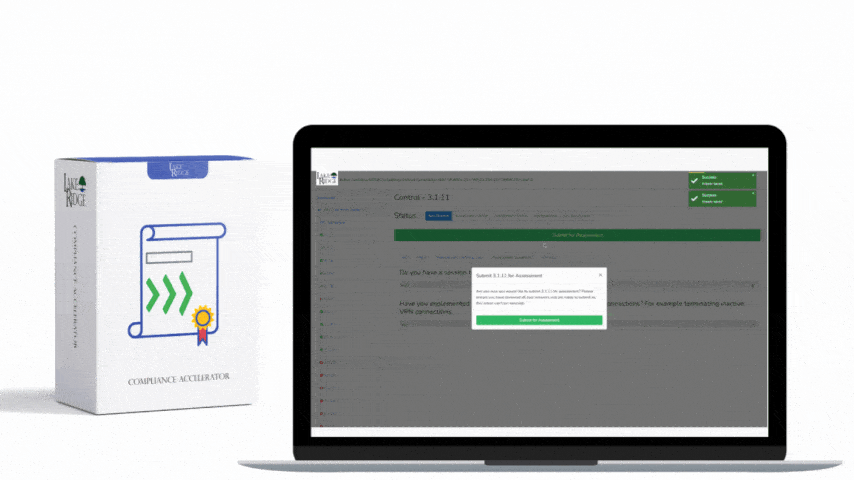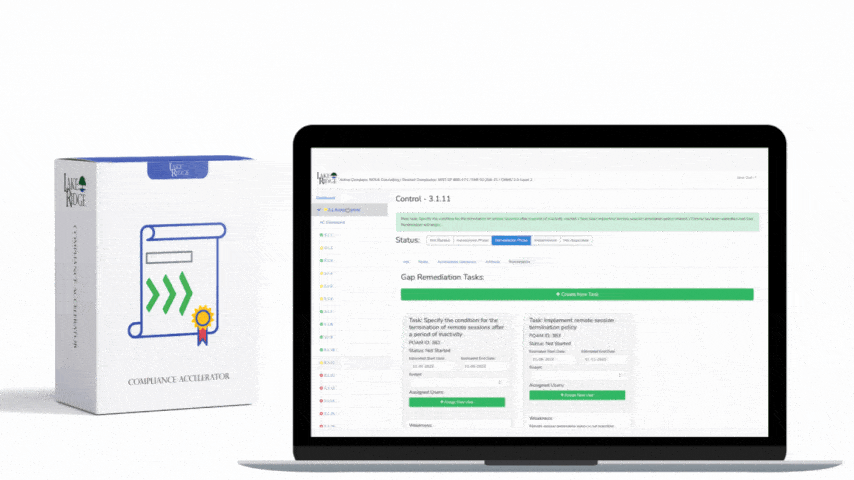
This control requires a documented, actionable incident and threat management capability that ensures your organisation can detect, assess, respond to, and recover from cybersecurity incidents. Per the Essential Cybersecurity Controls (ECC – 2 : 2024), the program should satisfy the set of objectives labeled 2-13-3-1 through 2-13-3-5, meaning you must define roles and responsibilities, detection and triage processes, escalation and communication paths, response and containment procedures, and post-incident review and improvements.
Technical Implementation
-
Establish an incident response (IR) policy and playbooks: Create a short incident response policy that defines scope, roles (incident owner, technical responder, communicator), severity levels, and SLAs. Build concise playbooks for common incidents (phishing, ransomware, data leak, suspicious external access) with step-by-step containment and evidence-preservation actions.
-
Deploy detection and logging with triage rules: Ensure centralized logging (SIEM, log collector, or cloud-native logging) for critical hosts, servers, and edge devices. Implement simple triage rules and alerts (failed logins, privilege escalation, unusual outbound traffic) that automatically classify incidents into the severity levels in your policy.
-
Define escalation and communication procedures: Create a clear escalation matrix mapping severity to personnel to notify (IT lead, CEO, legal, PR, third-party forensic vendor). Prepare templated internal and external communications and a secure channel (e.g., encrypted email or a private incident Slack channel) for the IR team to coordinate.
-
Containment, eradication, and recovery checklist: For each playbook include immediate containment steps (isolate host, revoke compromised credentials, block C2 domains), evidence capture (disk image, audit logs), eradication actions (remove malware, patch vulnerability), and recovery steps (restore from clean backup, validate integrity) with defined verification testing before return to production.
-
Post-incident review and continuous improvement: After every incident perform a documented lessons-learned review within a fixed period (e.g., 7–14 days). Update playbooks, detection rules, and training based on root cause analysis; track action items to closure and measure mean time to detect/respond (MTTD/MTTR).
-
Engage external support and reporting: Maintain relationships with a trusted external incident response provider and legal counsel; document when to escalate to them. Ensure compliance-driven reporting (regulatory notification thresholds, data breach obligations) is integrated into the playbooks.
Example in a Small or Medium Business
AcmeCo, a 75-person managed services provider, formalised Control 2-13-3 by creating a one-page incident response policy and three playbooks for phishing, suspected ransomware, and credential compromise. They designated an incident owner (IT manager), a technical responder (senior engineer), and a communications lead (operations manager). Logs from endpoint agents and the firewall stream into a cloud SIEM with three triage alerts tuned for their environment; when an alert hits a severity-2 threshold, the SIEM creates a ticket that triggers a phone and Slack notification to the IR team. During a phishing event, the team followed the playbook: contained affected accounts, reset credentials, preserved email messages for evidence, and pushed an emergency awareness bulletin to staff. They engaged their retainer forensic firm for deeper analysis and ran a lessons-learned session the following week to improve email filtering rules and add multi-factor authentication enforcement for legacy services. Over three months they reduced average time-to-contain by half and closed all corrective actions from the post-incident review.
Summary
Meeting Control 2-13-3 means putting in place a compact, practical incident and threat management program: clear policy, role definitions, detection and triage, escalation and communication, containment and recovery playbooks, and a structured post-incident review. For SMBs these measures are scalable and focus on practical automation (logging/alerts), repeatable playbooks, and relationships with external experts. Together, policy and technical actions reduce detection and response times, contain impact faster, and create a continuous improvement cycle that keeps your business safer with limited resources.