This post explains how to implement and prove compliance with the NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 control SI.L2-3.14.6 — monitoring inbound and outbound communications in cloud environments — with practical steps, technical examples, and sample evidence that a small business can use during an assessment or audit.
What SI.L2-3.14.6 requires (short)
The core expectation of SI.L2-3.14.6 is that organizations continuously monitor network communications (both inbound and outbound) to detect and respond to unauthorized or anomalous traffic that could indicate compromise or data exfiltration. For cloud-hosted systems that means collecting flow and packet- level telemetry, DNS/proxy logs, and system-level network events, converting telemetry into meaningful alerts, and retaining and documenting evidence that monitoring works as intended.
Practical implementation steps
1) Inventory and data-flow mapping
Start by documenting every cloud asset that initiates or receives traffic: VPCs/subnets, VM instances, serverless functions, container clusters, load balancers, and SaaS connectors. Produce a simple data-flow diagram that identifies which assets house Controlled Unclassified Information (CUI), the expected remote endpoints (vendor IP ranges, partner domains, cloud service endpoints), and approved egress paths (egress via proxy, NAT gateway, or direct). This map drives what you enable logging for and where to place controls.
2) Collect the right telemetry
Configure native provider telemetry first — it’s low cost and high value. Examples: enable AWS VPC Flow Logs (or Transit Gateway flow logs), AWS CloudTrail Data Events for S3, and AWS GuardDuty; for Azure enable NSG flow logs, Azure Monitor/Diagnostics, and Azure Defender; for GCP enable VPC Flow Logs and Cloud Armor. Also collect DNS logs (Route 53 resolver logs, Azure DNS Analytics, or internal DNS server logs), proxy/forwarding logs (e.g., Squid, Zscaler), and endpoint network telemetry (EDR such as CrowdStrike, Defender for Endpoint). A practical small-business tech stack could be: VPC Flow Logs + CloudTrail + DNS query logs + a cloud-native SIEM (Amazon Security Lake / Azure Sentinel / Elastic Cloud). Typical useful fields: source_ip, source_port, dest_ip, dest_port, protocol, bytes_in, bytes_out, action, timestamp, flow_start, flow_end, and instance_id.
3) Detection rules and alerting
Create detection rules tuned to your environment. Examples of rules you can implement immediately:
- Unusually large egress: sum(bytes_out) to a single external IP > 100 MB within 10 minutes.
- New external destination: host connects to an external IP not seen in the last 90 days.
- High cardinality DNS: single host queries > 50 unique domains in 10 minutes (possible beaconing).
- Suspicious protocol: outbound SMB, RDP, or database ports from endpoints that should not communicate externally.
Implement these as SIEM alerts (KQL for Sentinel, SPL for Splunk, or Elastic DSL). For example, a simple KQL example for Azure NSG flow logs: AzureDiagnostics | where Category == "NetworkSecurityGroupFlowEvent" | summarize bytes=sum(TotalBytes) by RemoteIP_s, Computer | where bytes > 100000000. Tune thresholds over 2–4 weeks to reduce false positives.
4) Blocking, containment and response
Monitoring must be tied to action. Use cloud-native controls to block or constrain traffic automatically or via an analyst workflow: update Network ACLs, apply NSG rules, add IPs to firewall blocklists, or quarantine instances via automation runbooks. For encrypted (TLS) traffic, place an egress proxy with TLS inspection (if permissible) or use SNI/JA3 fingerprinting in telemetry. Implement rate-limited blocking for suspected exfil events: e.g., temporarily restrict an instance to internal-only communications while the SOC investigates. For small businesses that lack 24/7 SOC, consider a managed detection and response (MDR) provider or automated playbooks using AWS Lambda or Azure Logic Apps to contain suspicious egress quickly.
Evidence to prove compliance
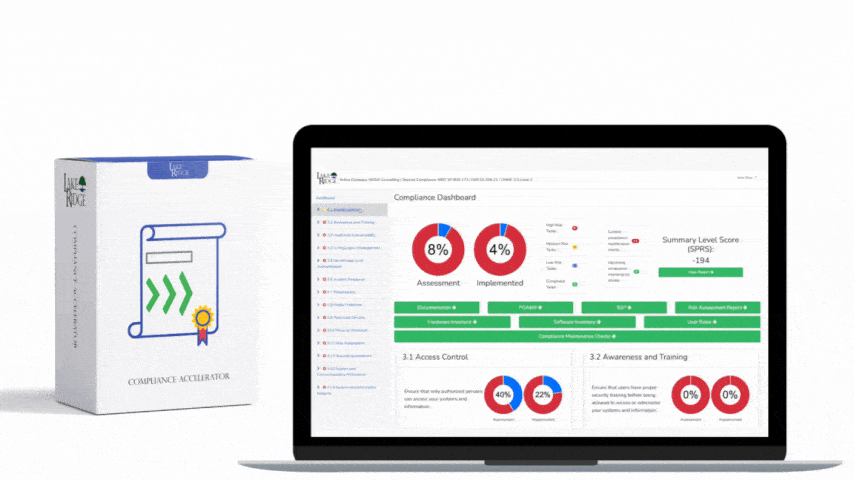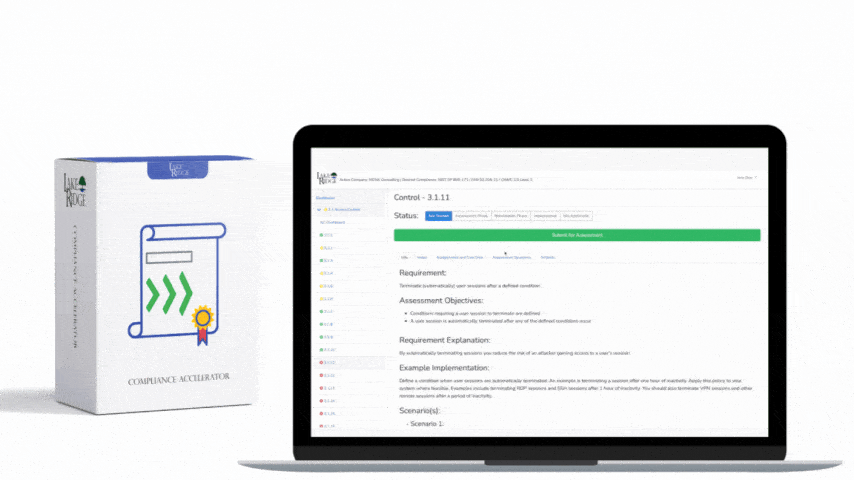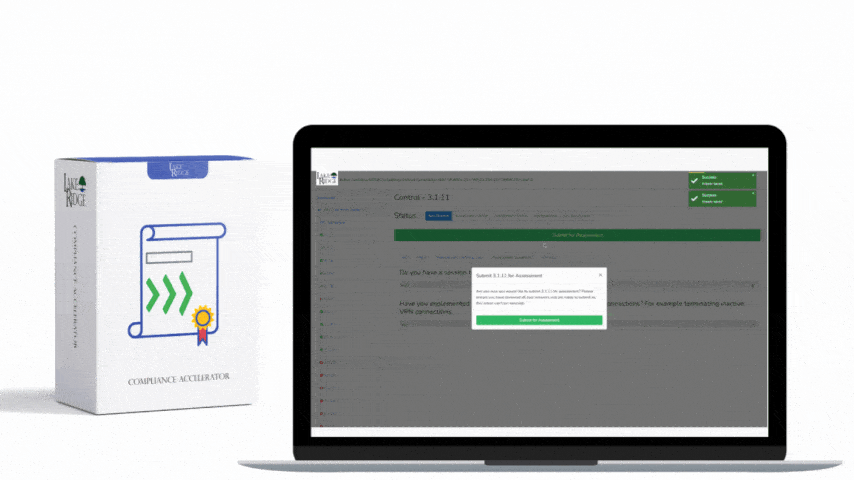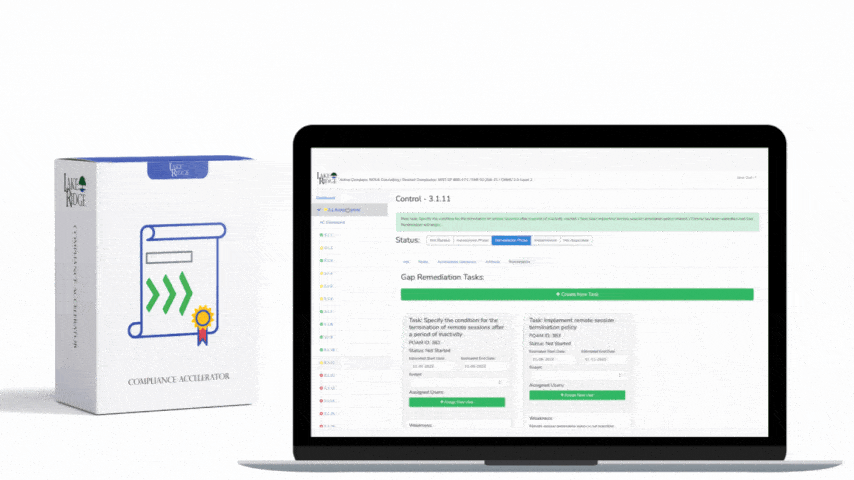
Auditors will want to see technical evidence that monitoring is enabled, effective, and operationalized. Useful artifacts: - Policies and procedures: Monitoring policy, alerting thresholds, retention policy. - Architecture and data-flow diagrams showing logging pipelines. - Config screenshots or JSON/YAML showing VPC Flow Logs/NSG Flow Logs enabled and pointing to the correct S3/Blob/Log Analytics workspace. - SIEM dashboards and saved queries with time-range exports that show detected incidents. - Example incidents and incident tickets (root cause, actions taken, timestamps). - Playbooks/runbooks used to respond to egress alerts and their execution history. - Log retention and acquisition proof (S3 bucket lifecycle or Azure retention compliance settings). Collect and timestamp these artifacts; include hashes or exports if auditors request immutable evidence.
Real-world small-business scenarios
Scenario A — accidental public S3: A developer misconfigures an S3 bucket and a CI runner starts uploading debug data containing CUI. Monitoring: S3 Data Events in CloudTrail plus VPC Flow Logs show new outbound PUTs to S3 with a developer's instance as source. Detection: alert on unusual PUT volume to external storage from a compute instance. Response: automated Lambda tags the instance, revokes IAM write permission to S3, and opens a ticket. Evidence: CloudTrail event JSON, VPC Flow Log lines, IAM change logs, and incident ticket.
Scenario B — stealthy exfil via DNS tunneling: An attacker uses a compromised VM to exfiltrate via DNS TXT queries. Monitoring: DNS query logs show high-entropy TXT requests and many unique subdomains. Detection: alert on high entropy (Shannon) of DNS query strings and high cardinality of subdomains per host. Response: block the instance at the NSG / security group level and perform forensic snapshot export. Evidence: DNS logs, flow logs showing DNS server as destination, alert rule, and containment action logs.
Risk of not implementing SI.L2-3.14.6
Without effective inbound/outbound monitoring you face undetected data exfiltration, longer dwell times for attackers, supply-chain and third-party compromise, contract loss (DOJ/DoD contracts often require CMMC compliance), and reputational damage. For small businesses that host or process CUI, failing an audit can mean lost contracts and mandatory remediation that is more expensive than implementing basic monitoring upfront.
Compliance tips and best practices
Practical tips: (1) Start small and iterate — enable VPC flow logs and DNS logging for high-risk subnets first. (2) Use the cloud provider’s cheapest archival storage for long-term retention (e.g., S3 Glacier / Azure Archive) and keep hot logs for investigation windows. (3) Baseline normal traffic and use anomaly detection to reduce false positives. (4) Document tuning decisions and justify thresholds as part of evidence. (5) Automate containment runbooks and record executions. (6) If you are resource-constrained, leverage managed services (MDR, CSPM, or security marketplace connectors) to fill capability gaps quickly.
In summary, meeting SI.L2-3.14.6 requires a repeatable program: map data flows, enable cloud-native and endpoint telemetry, implement tuned detections and playbooks, and assemble clear evidence (logs, queries, dashboards, and tickets). For small businesses the emphasis should be on practical, low-cost telemetry (flow + DNS + CloudTrail), sensible alert thresholds, and automated containment to reduce time-to-detect and time-to-contain — all of which you can capture and present during a NIST/CMMC assessment.