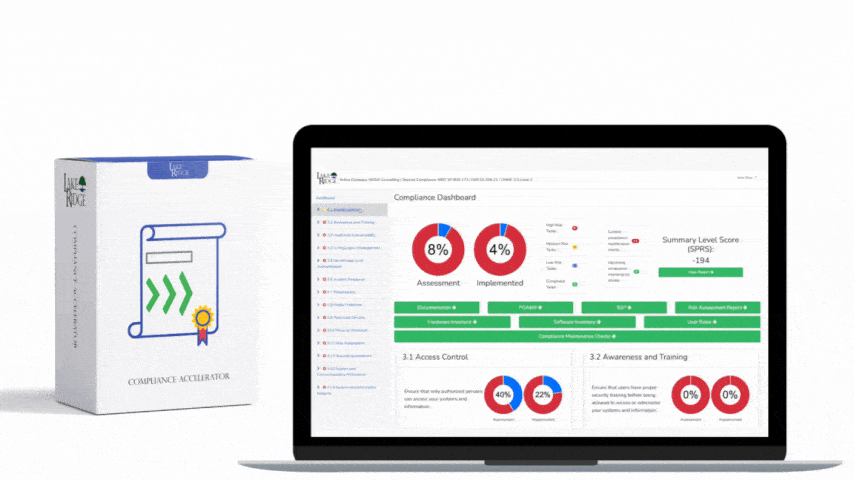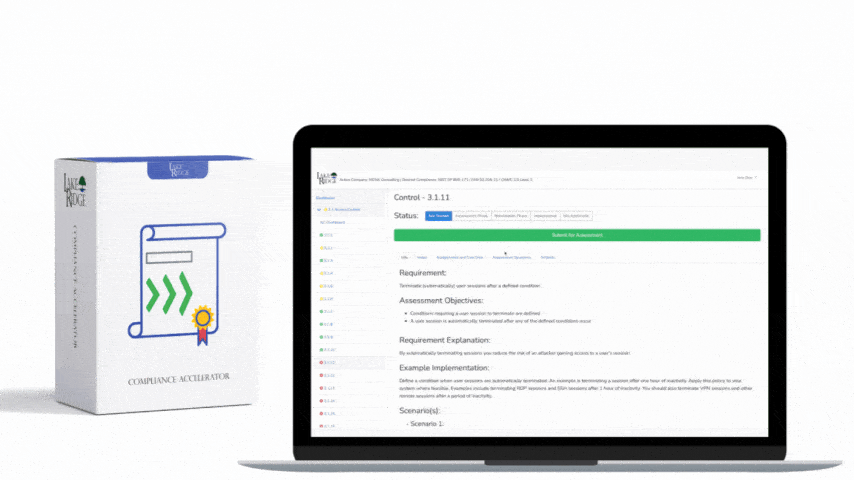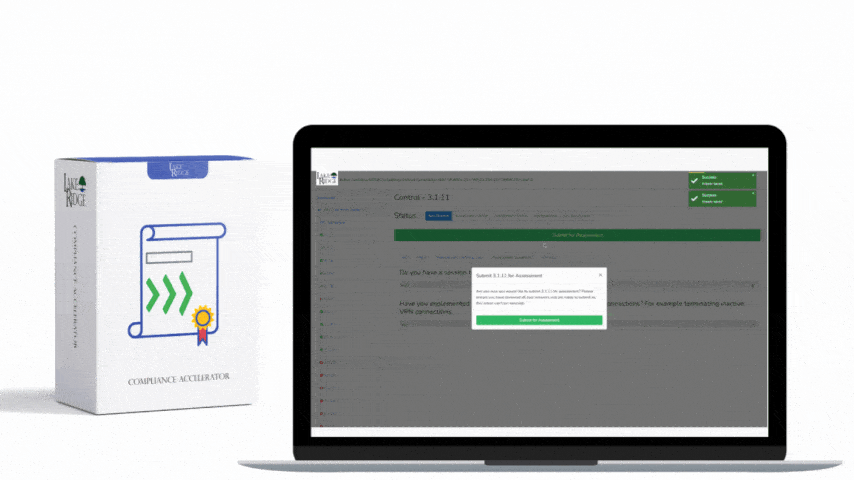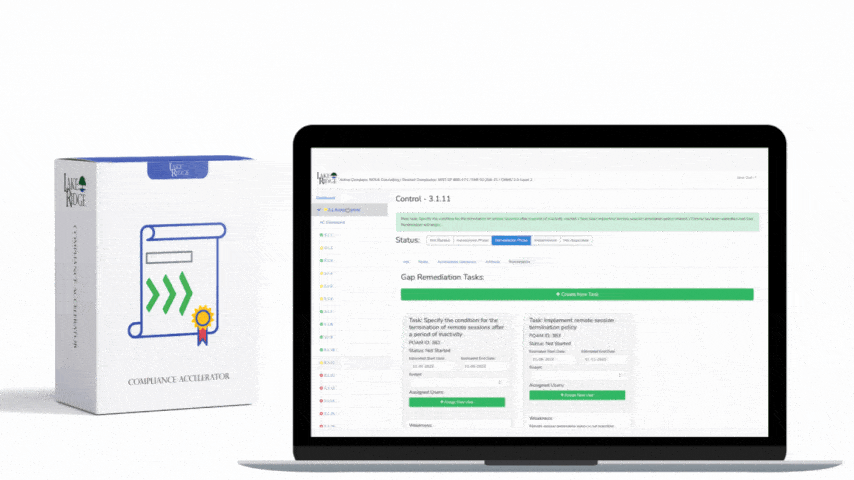
Monitoring security alerts and advisories and taking timely action is an explicit NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 requirement (SI.L2-3.14.3) that prevents compromise of Controlled Unclassified Information (CUI); this guide walks you through practical, auditable steps to establish a monitoring program, prioritize alerts by business impact, integrate with existing operations, and produce evidence for assessors.
What the control requires (plain language)
The control requires organizations to actively monitor security alerts and advisories from trusted sources and to take appropriate action when an alert affects systems that handle CUI. Practically this means subscribing to authoritative feeds, mapping alerts to your asset inventory and CUI stores, triaging and assigning mitigations within documented SLAs, and keeping records of decisions and remediation for audit evidence in your SSP and POA&M.
Step-by-step implementation
1) Build a reliable alert-source catalog
Start by subscribing to prioritized feeds: CISA KEV and CISA’s vulnerability bulletins, NVD JSON/RSS (for CVE & CVSS data), vendor PSIRTs (Microsoft MSRC, Cisco PSIRT, VMware, Adobe), cloud provider advisories (AWS Security Bulletins, Azure Security Center alerts), and 3rd-party library sources (GitHub Dependabot, Snyk, OSS advisories). For small businesses on a budget, focus first on CISA KEV, vendor advisories for key infrastructure, and GitHub Dependabot for source-code dependencies; automate ingestion via APIs or RSS-to-email connectors so alerts land in a centralized queue.
2) Map alerts to assets, CUI impact and criticality
Keep an up-to-date asset inventory that includes where CUI is stored or transits (e.g., file servers, cloud buckets, endpoint groups). When an advisory arrives, automatically or manually map the affected product/version to assets and annotate the asset’s CUI impact level. Use CVE+CVSS score augmented with exploitability indicators (CISA KEV, Active Exploits in the wild) to derive a risk score. Example: a critical CVSS 9.8 Windows RCE affecting your file server that stores CUI is high priority; a low-severity library issue used only in a dev environment may be lower priority.
3) Triage process, SLAs and playbooks
Create a simple triage workflow: (a) acknowledge within 8–24 hours, (b) risk analysis & assignment within 24–48 hours, (c) apply mitigation/patch or compensating control within defined windows (for small orgs, 48–72 hours for actively exploited criticals, 7–30 days for high/medium risks based on business impact). Develop playbooks for common types (OS patches, agent updates, configuration changes, library updates). Record triage notes, assigned owner, ticket numbers and final remediation steps in your ticketing system (Jira, ServiceNow, or even a spreadsheets backed by timestamps for very small teams).
4) Automate collection, correlation and response where practical
For technical implementation: ingest NVD JSON and CISA KEV via scheduled jobs; use SIEM or log aggregation (Splunk, Elastic, Azure Sentinel, AWS Security Hub, or open-source Wazuh/OSSIM) to correlate alerts with telemetry (asset tags, installed software lists, endpoint detection logs). Use orchestration (AWS Systems Manager Patch Manager, Microsoft Windows Update for Business, or Rundeck/Ansible playbooks) to automate patch deployment and to generate deterministic evidence (patch job run logs, return codes). Small businesses can use managed services — a managed detection and response (MDR) or vulnerability scanning subscription — to reduce operational burden while still meeting the requirement.
Real-world small-business scenarios
Scenario A: A 20-person contractor hosts CUI on an AWS EC2 instance and uses GitHub for code. Implementation: subscribe to AWS advisories and MSRC, enable AWS Inspector and AWS Security Hub to surface findings, enable Dependabot on repos, map EC2 tags to CUI, and set up an SNS topic that posts new critical alerts into a Slack #security-alerts channel and creates a Jira ticket. Triage policy: critical KEV hits — emergency patch within 48 hours; evidence: Slack thread, Jira ticket, AWS Systems Manager patch run output.
Scenario B: A small MSP managing multiple clients uses a central ticketing queue. Implementation: centralize vendor advisories into an email inbox monitored by the lead engineer; use a lightweight SIEM (Elastic Cloud) to correlate endpoint telemetry and prioritize alerts that correlate to active sessions or command-and-control indicators. If resource-constrained, subscribe to a vendor-managed patch service for endpoints and maintain a spreadsheet tied to the SSP listing alert subscriptions and remediation timelines for auditors.
Compliance tips, evidence and risks if you don’t implement
Compliance tips: document the alert sources and ingestion method in your SSP; keep a running POA&M for deferred remediations with clear dates and compensating controls; collect and retain artifacts — subscription confirmations, SIEM correlation logs, ticket IDs, patch deployment logs, and meeting minutes showing triage decisions. Recommended metrics: mean time to acknowledge (MTTA), mean time to remediate (MTTR), number of advisories that affected CUI, and number of mitigations applied. Retain evidentiary artifacts per your policy (commonly 12–36 months) for assessors.
Risk of non-implementation: failing to monitor and act on advisories increases the chance of compromise, data exfiltration of CUI, lateral movement by attackers, loss of DoD contracts, regulatory fines, and reputational damage. For example, an unpatched publicly exploited RCE on a web server that stores CUI can lead to immediate breach and contract termination; auditors will flag the absence of an operational alert-to-action program and corresponding evidence.
Summary: Implementing SI.L2-3.14.3 is a practical combination of subscribing to authoritative advisories, mapping alerts to CUI-bearing assets, establishing measurable triage SLAs and playbooks, automating collection/response where feasible, and maintaining audit-ready evidence (tickets, logs, SSP/POA&M entries). Small businesses can meet the control using a mix of automated feeds, lightweight SIEM or managed services, clear roles, and documented procedures that demonstrate consistent monitoring and timely action.