Meeting SI.L2-3.14.3 under NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 means not just generating alerts, but making those alerts meaningful, actionable, and auditable; this post provides practical, step-by-step guidance for tuning detection systems, cutting false positives, and prioritizing response actions so a small organization can demonstrate compliance while actually improving security outcomes.
Key objectives and compliance context
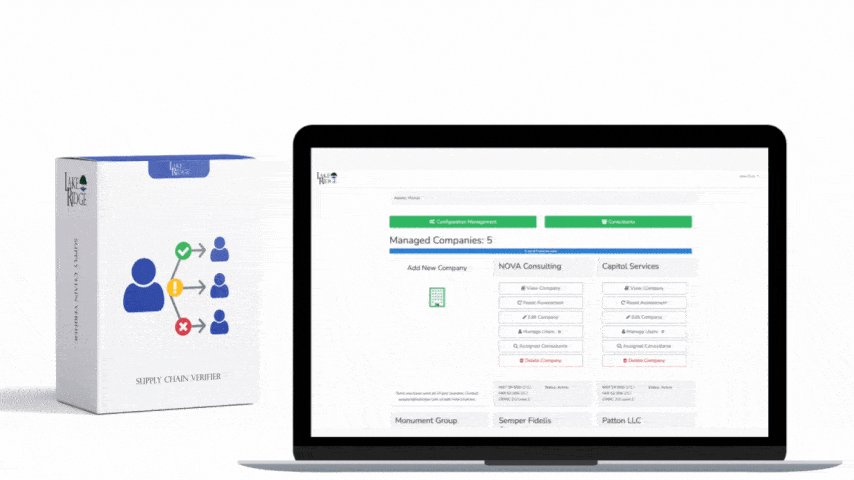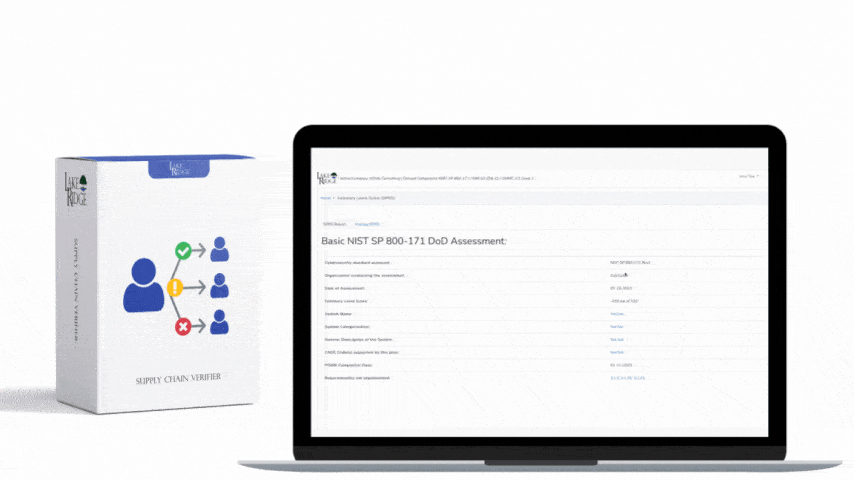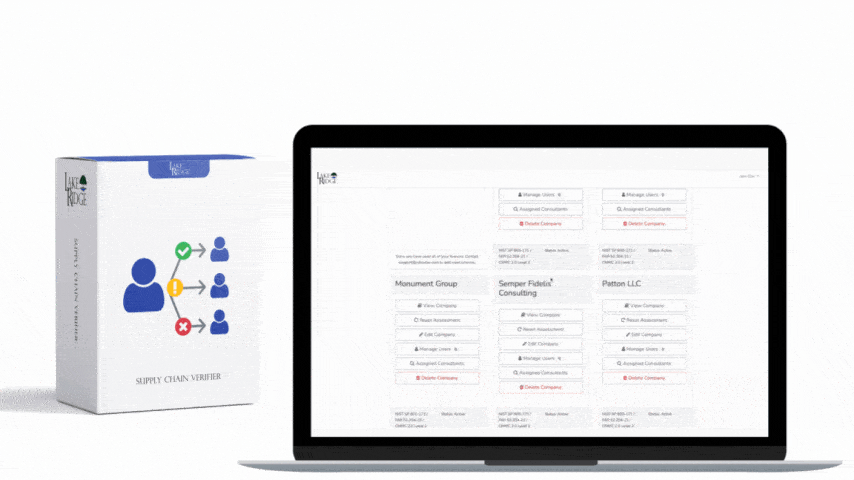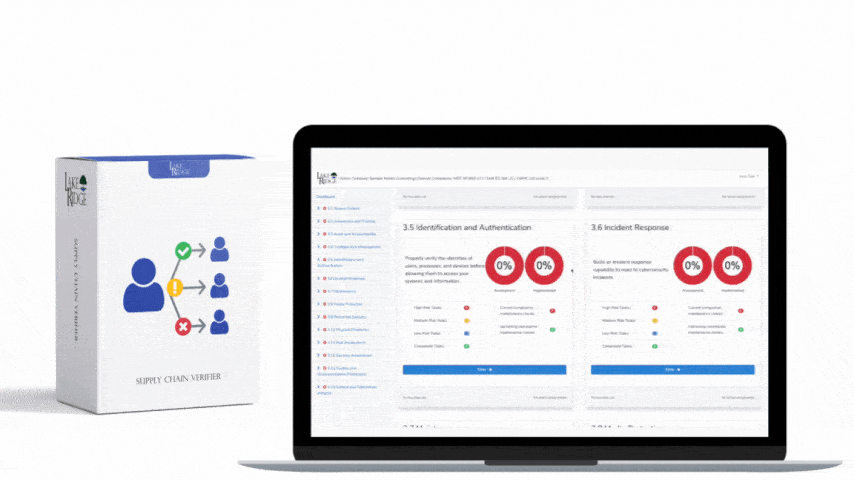
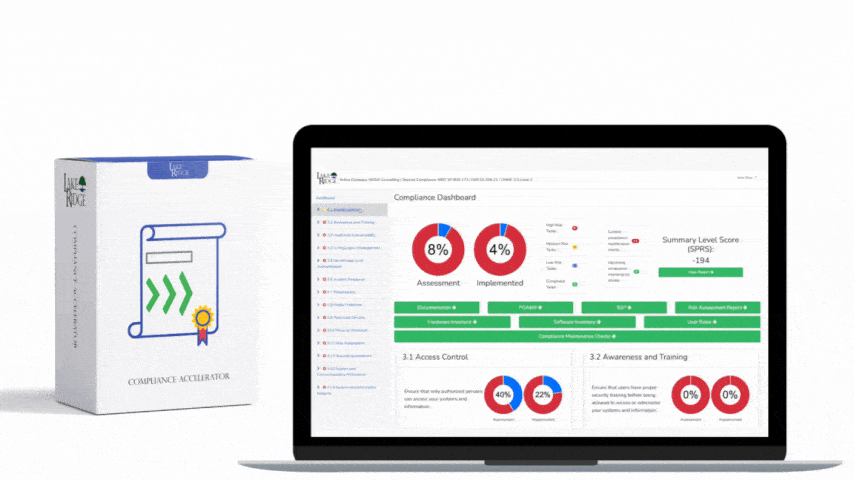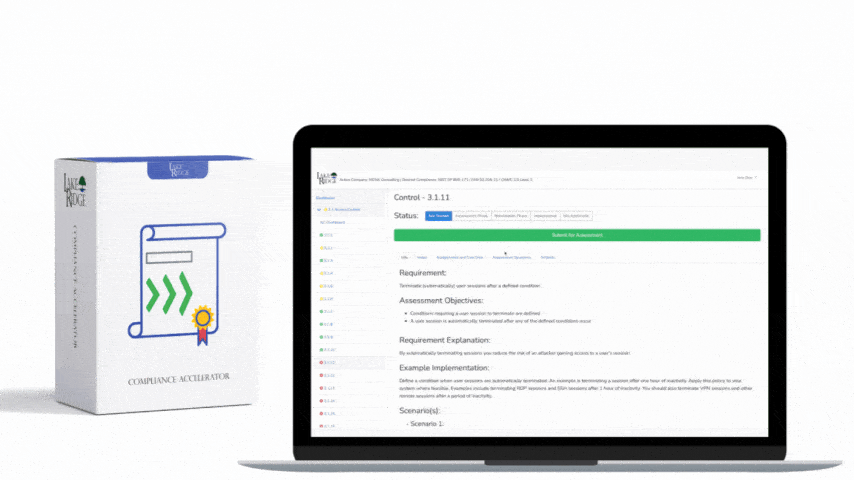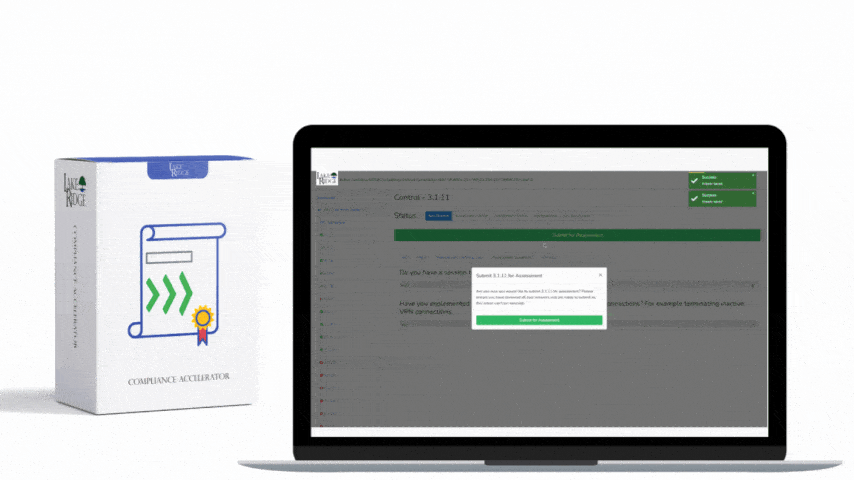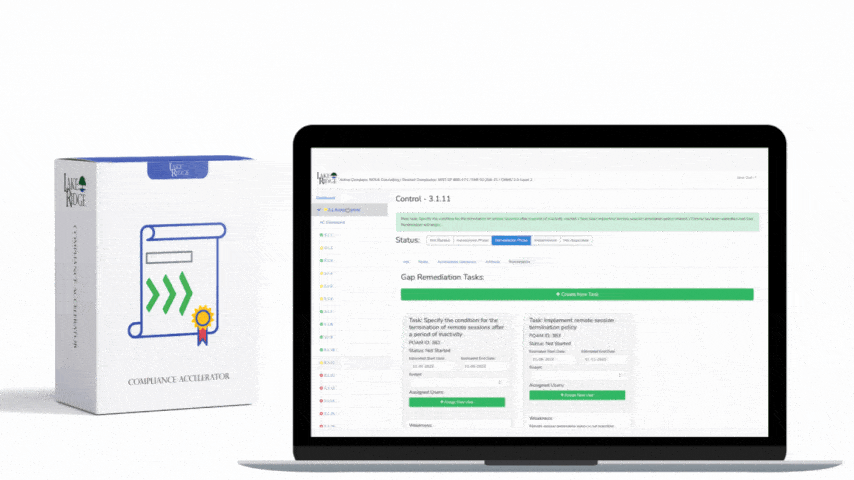
The goal for SI.L2-3.14.3 is to ensure that security event sources and detection tools produce reliable alerts that support timely and effective response to threats affecting Controlled Unclassified Information (CUI). For compliance, you must show: an inventory of event sources, documented tuning activities, role-based alert handling procedures, and metrics demonstrating improvements (for example, reduced false positive rates and mean time to respond). Implementation must be repeatable and retained for audit evidence.
Practical implementation steps
1) Inventory assets, event sources, and use cases
Start by cataloging all telemetry and event sources: endpoint EDR/EPP, firewall logs, IDS/IPS, Windows event logs (4624/4625/4688), VPN and cloud access logs, mail gateways, and vulnerability scanners. Define the critical assets that process or store CUI and tag them in your SIEM/XDR. For each source create a small set of prioritized use cases (e.g., brute-force logon attempts, suspicious process creation, data exfil over non-standard ports). Document the mapping from asset to alert type for audit evidence.
2) Baseline normal behavior and tune thresholds
Collect 14–30 days of telemetry to establish baselines. For example, compute average failed SSH logins per IP per hour and set rules like "failed logins > 20 from a single IP in 10 minutes" rather than alerting on every failed attempt. For EDR detections, use confidence and severity fields: suppress low-confidence signatures on non-critical hosts and increase sensitivity on domain controllers or CUI servers. Specific example: change a rule from "file hash match -> alert" to "file hash match on CUI-server OR followed by outbound connection -> high-priority alert".
3) Correlation, enrichment, and prioritization
Use correlation rules to combine low-fidelity events into high-fidelity alerts. Enrich events with asset criticality, user role (admin vs. standard), geolocation, and threat intelligence (IOC reputation). Prioritization matrix example: Score = (asset_criticality * 3) + (threat_reputation * 2) + (confidence). Route high-score alerts to senior analyst queue and low-score to automated investigation or ticketing only. For small teams, focus human review on alerts scoring above a defined threshold (e.g., score ≥ 7/10).
4) Suppression, deduplication, and scheduled maintenance windows
Suppress known noisy conditions: vulnerability scans, backup jobs, software deployments, and scheduled vulnerability scans should be whitelisted or matched to a "maintenance" tag so they don't generate production alerts. Implement deduplication rules (group identical alerts within a time window) to avoid repeated incidents. Example: dedupe identical firewall drops from the same IP for 15 minutes and increment a counter rather than creating new tickets for each packet.
5) Automation, playbooks, and SLA-driven routing
Create simple playbooks for common high-priority detections: contain endpoint, isolate network segment, collect forensic artifact, and escalate to CISO. For small businesses, automate enrichment and triage tasks (reverse DNS, WHOIS, internal asset lookup) using SOAR or scripts to speed decisions. Define SLAs based on impact: critical (CUI exfil risk) — respond within 1 hour; high — 4 hours; medium — 24 hours. Connect alerts to ticketing systems with pre-populated fields to reduce follow-up time.
Real-world small business scenarios
Scenario A — Internal vulnerability scanner generates thousands of IDS alerts every night: Tag the scanner IPs and create a "scanner" context so its traffic is ignored for low-severity IDS rules and only tracked by scan-review rules. Scenario B — A managed service provider (MSP) running EDR sees dozens of low-confidence detections from user-installed developer tools: maintain a software allowance registry and suppress specific detections on inventoried developer machines during working hours. Scenario C — Multiple failed RDP attempts from a foreign IP: correlation ties failed logons to unusual process creation and a sudden large outbound transfer — escalate as high-priority and initiate containment playbook immediately.
Compliance tips, evidence, metrics, and risks
Keep a tuning log as part of your compliance artifacts: date, rule modified, reason, expected impact, who approved, and testing results. Track metrics: false positive rate, alerts per day, mean time to acknowledge (MTTA), and mean time to remediate (MTTR). Not implementing these controls risks alert fatigue, missed true incidents, CUI exposure, failed audits, and potential contract loss with government customers. Auditors will expect not only technology but documented processes, approval records, and evidence of continuous improvement.
Summary: To meet SI.L2-3.14.3 you must move from noisy telemetry to a measured detection and response program — inventory and tag assets, baseline behavior, tune thresholds, correlate and enrich events, suppress known noise, automate triage, document every tuning decision, and measure outcomes; these steps reduce noise, improve detection quality, and provide the auditable evidence required for NIST SP 800-171 Rev.2 / CMMC 2.0 Level 2 compliance.